皆さま、こんばんは。
このような辺境まで、お越し頂き、ありがとうございます。
Twitterやネットでの情報を追っている皆様は、既にご存じかと思いますが、先日とある画像生成AIが公開されました。
それが、表題にもあります「Stable Diffusion」です。
そんな今話題のStable Diffusionについて、相変わらずのポンコツな私が使用できるようになるまで苦労したことや、その手触り感について書き残しておきたいと思います。
【注意】
この記事は主に、プログラム関係に馴染みのない方に向けて作成しております。
私はあまり知識が深くないので、今回も凄ーくどうでもいい事で苦労していますので、既にその手の方面に知識のある方には理解できない部分で躓いているためイラっと来る人もいらっしゃると思います。
知識の深い方には、素人が右往左往する姿を楽しむ位しかできない記事かと思いますので、そのつもりでお進みください。
Stable Diffusionって何?
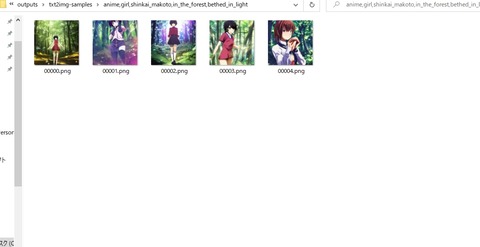
nnここ数日話題のお絵描きAIであるStable Diffusionちゃんですが、簡単に言うと与えたキーワードを基に絵を描いてくれるというものです。
私は絵心がまるでないおっさんなので絵を描くことは早々に諦めて、この様に文章を書くことを趣味としているのですが、やはり絵を描きたいという憧れはあります。
自分の脳内にあるこの絵を表に出せたら楽しいだろうなぁと言う漠然とした想いはあるのです。
ですが、流石にその為に絵を描く事を目指すのは、特に今の私には厳しいです。
しかし、そこで青天の霹靂の如く、Stable Diffusionが登場しました。
凄い世の中になったものです。
そして興味をもって調べてみたのですが、調べれば調べるほど凄い子でした。
ここ最近、トレンドとして挙がっているお絵描きAIなのですが、この記事にありますとおり先輩に「MidJourney」がいます。
ですが、このMidJourneyさんは、残念ながらお金がかかるので無節操に楽しむことはできませんでした。
あとDiscordを使うという事で、私はちょっと良く分からなくて敬遠していたのもあります(超個人的な理由)
しかし、今回、発表された「Stable Diffusion」は、ななな、なんと無料!
オープンソースなので自分でカスタマイズもできそうですし、これは私にも手が出るのでは!?
そう思った時期が私にもありました(遠い目)
まぁ、そんな訳で文字をつなげて絵を描く為、私のポンコツな頭でStable Diffusionを使えるようになるまでのお話が、今回の記事の趣旨です。
もし私と同じように、ちょっと遊んでみたいなぁ、けど難しそうだなぁというプログラム初心者の皆さんに向けて、何かの参考になれば幸いです。
Stable Diffusionを使ってみよう!
と、書きましたが、私が調べて色々試した結果、何通りか方法があることが分かりました。
その前に、私のPC環境をある程度こちらに記載しておきたいと思います。
・CPU
Core i7-12700

・OS
Windows 10
・私の知識レベル
Java ScriptやGASなら書けるくらい
Python?最近流行ってるよねーくらい
開発環境? 何それ美味しいの?(テキストベタ打ち)
上記のような状況で、いざスタートです。
勿論、今回も苦労したよ!
いきなり結論 初心者&マシンスペック低ならGoogle一択
どうでもいい話ですが、私は割とGoogle信者なので、「ははぁ!ぐーぐるさまぁ!!」ってなってます。
そんな私の様にならないまでも、別にGoogle嫌いじゃないよ、という方で、
プログラム?わからん!な人
グラボがNVIDIAじゃない人
PCが私のPC以下のスペックの人
こういう方は、選択肢は一つだけです。
迷わずGoogle様のお世話になりましょう(言い方
信仰的に問題のない方は、まずはGoogleアカウントを作っておきましょう。
もし仮に作成が不安な方は、以下のサイトを参考にして作ってください。
作成にはスマホなどでメールを受け取る必要があります。
Google信者の皆様ご用達なPixcelでは、通知等でより簡単な環境で接続できます。
もしGmaliを持っていて、Googleアカウントのある方は先に進みます。
具体的なやり方は、以下のサイトに詳しくあります。
このサイトとGoogleに感謝しつつ、一つ一つその通りにやっていけば問題ありません。
後は、ゆっくりと楽しんで下さいね!(終了
私はローカル環境で楽しみたい!な人【まずは結論】
さて、私は最初、ローカル環境での構築を選びました。
Pythonの勉強がてらやるべーと、甘い気持ちで始めたのですが……いやぁ、まぁ、何も知らん状況で始めたので、そりゃ色々なところで突っかかりました。
で、現状、最終的にどうなったかと言うと、以下のサイトのお世話になりその通りに構築して、何とか動いてます。
サイトの主様と、情報提供して下さった多くの皆様に感謝!!
ちなみに、上のサイトの通りに環境構築をしても、実は私の環境では以下のような真っ黒・もしくは真緑の画像になってしまい、上手くいきませんでした。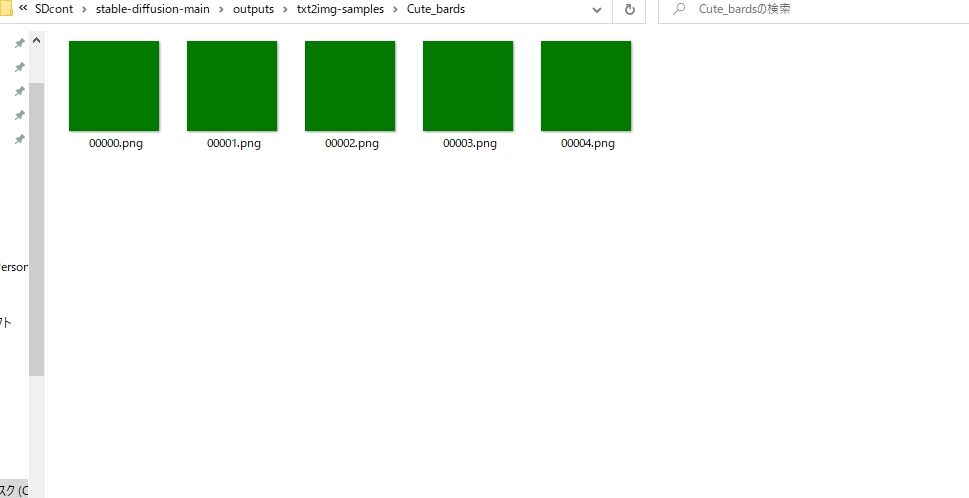
で、ここにたどり着いたのが、最終段階だったので、何でそうなっているかは既に分かっていました。
結論から言いますと、グラボがうまく対応できてないという事らしいです。
このサイトにある通りGeForce1660Superは、乗ってないんですよ。
つまり完全には対応できてない可能性が高いという事です。
で、さらに調べると、どうやら解決策があるとのこと!
これも結論から言うと、
–precision full
これをオプションに加えることです。
こうして動かすと、ついにちゃんとした画像が!!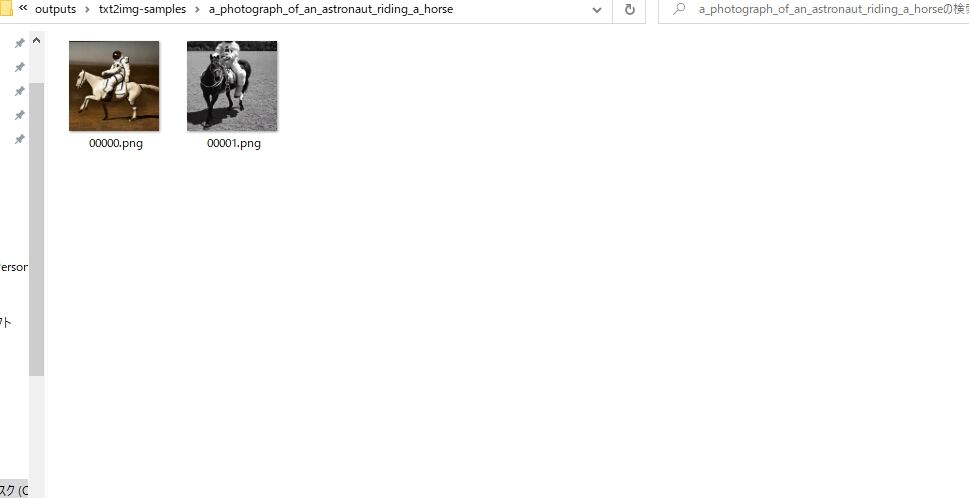
長かった、長かったよ。ここに至るまでは、本当に長い道のりでありました。
いや、そりゃなんも知らんところからのスタートなので、2日くらいぶっ通しで調べたよね。
という訳で、上の環境で使う場合は、こんな感じで動かしました。
python optimizedSD\optimized_txt2img.py --prompt "ここに呪文を書く" --W 256 --H 256 --ddim_steps 50 --n_samples 5 --n_iter 1 --precision full
何も分からんという初心者な方は、参考までに。
まぁ、という訳で結論としてはそれで、チャンチャンという話なのですが、実は今の状態でもいまいち何をどうやっているのかわかってなかったりします(恐ろしい)
う、動けばいいのよ、動けば!!
という訳で、ここからは、現状にたどり着くまでのお話を時系列で残しておきたいと思います。
またも始まる右往左往の時間
毎度ながら、全く知識がない状態から始めるものですから、本当に???という時間が続きました。
最初に参考にさせて頂いたのは、以下のサイトです。
このサイトを通して、かなり知識が深まりました!(多分)
ありがとうございました。
結論から申し上げますと、こちらのサイトの通りに構築して、動くところまでは行きました。
途中、CUDAのバージョンがあってなかったのでうんぬんかんぬんとか、PATH繋げられなくて、コマンド通らないとか、そもそもコマンドの打ち方がわかんねー!?とか色々ありましたが、それはさておき。
で、最終的に四苦八苦しつつも、出力は出来ました。
上の黒や緑の画像だらけになり、調べた結果、先に述べた通り「–precision full」をオプションに設定すればいいという事までは突き止めたんです。
突き止めたんですが……非常に初心者的かつ根本的な問題にぶち当たりました。
オプションの設定の仕方が意味わからん
とりあえず上記サイトや、公式の通りpipe()の中にカンマで区切って記述してみたのですが……エラーの嵐で???となりまして。
公式サイトの記述なども参考にしつつ、
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=15, generator=generator)["sample"][0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
image = pipe(prompt,precision=full )["sample"][0]
とか書いてみたら、めっちゃエラー。fullなんて引数ねぇよ!って怒られました。
え?だってfullってかいてあるじゃーん。
※以下公式からの引用です
usage: txt2img.py [-h] [–prompt [PROMPT]] [–outdir [OUTDIR]] [–skip_grid] [–skip_save] [–ddim_steps DDIM_STEPS] [–plms] [–laion400m] [–fixed_code] [–ddim_eta DDIM_ETA][–n_iter N_ITER] [–H H] [–W W] [–C C] [–f F] [–n_samples N_SAMPLES] [–n_rows N_ROWS] [–scale SCALE] [–from-file FROM_FILE] [–config CONFIG] [–ckpt CKPT][–seed SEED] [–precision {full,autocast}]optional arguments:-h, –help show this help message and exit–prompt [PROMPT] the prompt to render–outdir [OUTDIR] dir to write results to–skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples–skip_save do not save individual samples. For speed measurements.–ddim_steps DDIM_STEPSnumber of ddim sampling steps–plms use plms sampling–laion400m uses the LAION400M model–fixed_code if enabled, uses the same starting code across samples–ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling–n_iter N_ITER sample this often–H H image height, in pixel space–W W image width, in pixel space–C C latent channels–f F downsampling factor–n_samples N_SAMPLEShow many samples to produce for each given prompt. A.k.a. batch size–n_rows N_ROWS rows in the grid (default: n_samples)–scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) – eps(x, empty))–from-file FROM_FILEif specified, load prompts from this file–config CONFIG path to config which constructs model–ckpt CKPT path to checkpoint of model–seed SEED the seed (for reproducible sampling)–precision {full,autocast}evaluate at this precision
これを見る感じだと、他のオプションは変数に=で代入するだけだから、いけそうなものですが、ダメでした。
で、数字はが何故か入ったので、最終的に100億位入れてみましたが通るものの反応せず。
image = pipe(prompt,precision=max )["sample"][0]
そして何故かこれだと通る。なんで? けど反応は無し。
うーむ、もしかして……と嫌な予感がしたのでオプションの他の項目をいじった結果。
全く息をしていないことが判明しました。
わ、わからねぇ。なんでそんな意味不明な挙動をしているんだ!?
とまぁ、そういう訳で、じゃあ、公式の通り–が付くような入れ方が出来れば解決するんじゃないかなー?と思ったのですが、ここでまた初心者的な問題が。
え、どうやったらその入れ方ができるようになるの?
勿論、この疑問が出る通り、コマンドプロンプトでもpythonでもコマンドは弾かれてます。
因みにこの時点での私の作業はこんな感じ。
① コマンドプロンプトを管理者権限で立ち上げる
② cd でファイルの保存場所に移動
③ pythonコマンドで、python起動
④ お世話になったサイトを参考に以下のようなコマンドを張り付け
import torch
from diffusers import StableDiffusionPipeline
from torch import autocast
MODEL_ID = "CompVis/stable-diffusion-v1-4"
DEVICE = "cuda"
YOUR_TOKEN = "コピーしたアクセストークン"
pipe = StableDiffusionPipeline.from_pretrained(MODEL_ID, revision="fp16", torch_dtype=torch.float16, use_auth_token=YOUR_TOKEN)
pipe.to(DEVICE)
prompt = "a dog painted by Katsuhika Hokusai"
with autocast(DEVICE):
image = pipe(prompt)["sample"][0]
image.save("test.png")
多分、何か通してる環境が違うからコマンドも違うんだろうけど……そもそもpython –的な書き方をする場合は何を使ってるんだろうか?
結局実は今もって、何がどうして動いているのかいまいちわかってません。
ふわっとですがマニュアルを読み進めてきた感じだと「txt2img.py」に定義されているローカルルールっぽいので、つまるところ「txt2img.py」を起動できればいいんですけど……よーわからん。
そのままコマンド叩いても勿論、パスが無いので繋がらんけどその辺りの仕組みを理解しようとしたらあと数日かかりそうだったので、最終的に脳死で環境構築が出来たやり方に落ち着きました。
とりあえずそんな訳で、一応のゴールに到達したわけですが、忘備録ついでにPython初心者の私が凄く困った事を残しておきます。
【python初心者が超困った事】
Q: pip? git? conda?どこで入れるの?
Ans コマンドプロンプトから直接GO(phytonに入ったら>>>になったらダメ)
Q: pythonからコマンドプロンプトに戻れない!?
Ans いいか、落ち着いて「exit()」と入力するのじゃ
Q: そもそもgitコマンドって何よ
Ans 何か色々ダウンロードできるらしいけどよくわからんので使ってない
その後調べたらこんな感じっぽかった。
単純にCloneコマンドを使う場合はこういう事らしい。
Q: そもそもAnacondaって何よ
Ans 開発環境を構築して管理しやすくするものっぽい?
ldmなどのコマンドはこれに関するものっぽい
以上、右も左もわからない初心者の感覚だとこうなりますので、もし初心者向けに記事を書く方は何かの参考にして下さい。
いでよ美少女! 呪文生成の儀式
という訳で、現状、色んな表現を試して遊んでいるわけですが、結論から申し上げますとアニメ系はきつい。以上。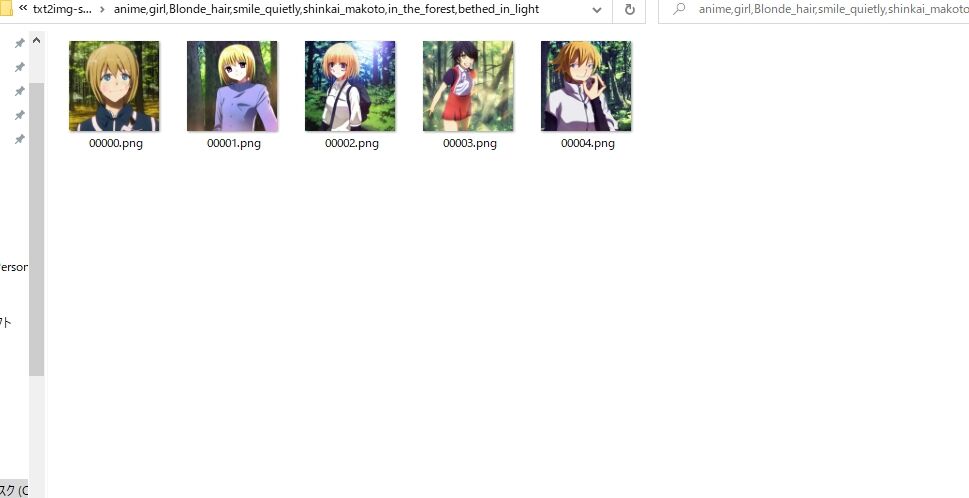
遠めに見ると割と行けてそうな感じじゃないですか。
近くで見ると凄いんですよ、これ。
あれ、手が無い、指が無い、頬どこいった?みたいな軽くホラーになってます。
何かこの作業していると、鋼の錬金術師思い出すんですよね……(遠い目
で、一応、参考としてこんなサイトもありますのでご紹介しておきます。
ですが、私は一つだけ注意しなければならないと思っていることがありまして。
それは、現在ご存命のアーティストさんをキーワードに選ぶ場合は少し慎重になった方が良いかもという事です。
まぁ、個人で楽しんで「わーいたのしー!」するくらいなら良いと思うのですが、外に出す場合(SNSに乗せるとか)は、ちょっと一旦待った方が良いかもです。
この辺りは今後の世の中の動きでどうなるか分かりませんので。
この技術自体が世に出たばかりの生まれたての赤ん坊のような存在なので、場合によってはこれからドンドンと大変な事になっていくことは想像に難くありません。
今回私がいち早く手を出したのは、もちろん、興味が9割くらいあるのですが、こうした楽しみ方が早いうちから出来なくなるかもしれないと思ったからです。
世の中の情勢に詳しい方ならご存じかと思いますが、難癖をつけて新しいものを抑えようとする動きはどこにでも起こるものですので。
なのでとりあえず、変に巻き込まれない程度に、外に出す絵に関してはキーワードについては、気を付けておいた方が良いと個人的に愚考した次第です。
勿論、単なるおっさんの一個人の意見に過ぎませんので、判断は皆様にお任せします。
そんな感じで最後は少し暗い話となりましたが、まだまだ可能性に満ちたStable Diffusionについて、興味のある方の参考になれば幸いです。
※2022年10月15日追記
この続きの記事ができましたのでリンクを張っておきます。
今回の記事は以上になります。
お読みいただき、ありがとうございました。


コメント
こんにちは
AIの作成した画像のネタスレッドを最近見てここまで来たのかと感心しました。
確かにアイコンくらいの状態で見ると良さげなのですが、
100%のサイズで見ると顔や体の一部がありえない形状をしていて
漫画ブリーチの「ホロウ化」したように見えましたw
進歩の早い世界ですから2-3年後には本職のイラストレーターのような
画像が生成できそうですね。
IT業界の底辺労働者としては「あいまい」である絵が描けるような
ソフトが一般に公開されている時代になったことが驚きです。
>>1
木村昌福さんへ
こんにちはー。
おお、こんなド辺境にコメントありがとうございます。
普通に使うとアニメ絵の場合、割とエグイ絵ができるのですが他の魔術師達は凄いですね。これ、まさに秘術とか呪文のレベルですよ。
このサイトに乗せた絵も、小さいと映えるのですよね。近視の人ならちょうどいい感じ。
でも近づくと、木村昌福さんの仰る通りとんでもないので、ここをどうするかが腕の見せ所なのでしょうか。
ブリーチ見たことないのでホロウ化がわからなかったのですが、調べて納得です。
うん、確かに!
しかし、この手の技術は一回走り出したら凄いものになりそうです。
そうなんですよ、絵の精度的にもう来年位には実用レベルになるんじゃないでしょうかね?
まぁ、生成させ方が全くわからんのですが(本末転倒)
私もIT系にちょっとだけ席を置いた身としては、ついに来たかと言う感じです。
いずれは来ると思っていましたが、何だかんだで色々と社会情勢が移り変わっていたので、もうちょっとかかると思っていました。
多分、感動できる文章や曲なんかもいずれAIが勝手に作る時代になると思います。
人間はその味付けや方向性を決めて取捨選択しプロデュースする側に回るでしょうね。
正に魔術師。以前、初音ミクが来た道を急速に駆け上がっている感じでしょうか。
私たちが生きている間に、そんな世界が来るとどうなるか、見届けたいものです。
ではではー。