
皆さま、こんばんは。
このような辺境まで、お越し頂き、ありがとうございます。
Twitterやネットでの情報を追っている皆様は既にご存じかと思いますが、日々、画像描画AIの進歩が止まりません。
一応、今は画像描画AIの祖ともいえる「Stable Diffusion」だけでなく、沢山のモデルが世に出ておりますが、私は敬意を表して今後も描画AIの事を表す言葉として、Stable Diffusionとして語りたいと思います。
で、そちらを何とかローカル環境で使おうと奮闘したのが、前回までの記事の内容になります。
いやぁ、相変わらずわからない事だらけで苦戦しております。
そして何度も書いておりますが私のやっていることはあくまで基礎レベル&めちゃくちゃ古いのですが、毎日のように一定数の迷い子達が訪れてくれておりまして、相変わらず私が思ってもみなかったレベルで読まれているようです。
時期的なものもあってか、今までPCのスペックが足りなかった方やPC自体に触れたことのない方が来ているのかな?
学生さんとかも新しい環境になって、PCに触れるようになる機会が増えそうですしね。
やはり皆さん、気にはしているし潜在的な需要自体は非常に高いんだなぁという事を改めて感じます。
そこで、今回は現時点で一番タブーなお話をする記事を書きました。
時期が時期なので、正直かなり長い期間、お蔵入りさせてた記事なんですよ、これ。
前回からトレーニング(ファインチューニング)という、ある意味禁忌の扉を開ける記事を書きました。
それは、記事に書いた通り避けて通れない事だと改めて私が感じた上で、その技術を特に絵師の皆様にちゃんと知っておいて欲しいと感じたからです。
私の認識では、今回の記事をもって現在のトレーニングを制することになります。
それでかなりの精度でトレーニングを生かすことができるようになるので、毎度ながらこの記事を書くかは本当に迷ったんです(いつもの
今回のトレーニング方法は、今まで以上に成果が手軽に得られる上に再現率が凄いんです。
ただし触ってみればわかりますが、それはそれとして、それなりの理解度と専門性が必要とされます。
ただ、昔から触ってきた私の感触としては、更に楽になったな!トレーニング!!と言う感じです。
そう言う所も含めて、今回も語りながらも相変わらずのポンコツな私が使用できるようになるまで苦労したことや、思うところについて書き残しておきたいと思います。
【注意】
今回は、トレーニングについての記事になります。
その為、著作権や絵師様への配慮等、様々な問題に絡みますので、くれぐれもこの技術の使用には細心の注意をもって対峙して下さい。
特に、現時点で絵師の許可なしにその絵を使ってトレーニングすることはお勧めしません。
また、この記事は主にプログラム関係に馴染みのない方に向けて作成しております。
私はあまり知識が深くないので、今回も凄ーくどうでもいい事で苦労していますので、既にその手の方面に知識のある方には理解できない部分で躓いているためイラっと来る人もいらっしゃると思います。
知識の深い方には、素人が右往左往する姿を楽しむ位しかできない記事かと思いますので、そのつもりでお進みください。
また、最近のAI技術の進歩が速すぎて、サクッとこの記事の内容が古くなる可能性が高いです。
その点を念頭に置いた上で、お楽しみくださいませ。
LoRAとは何?

nn以前の記事で触れた、Stable Diffusion web UI(AUTOMATIC1111版)にデフォルトで搭載されているトレーニング機能ですが、こちらは「Textual Inversion」ベースの技術となります。
こちらの機能はStable Diffusionが世に出てから初期の段階で登場したトレーニング方法です。
それに対して、前回ご紹介したのは「Dream Booth」というものです。
こちらは、Stable Diffusionが話題になって少しして世に出てきました。
そして、今回の記事で扱うのは「LoRA (Low-Rank Adaptation) 」と言うものです。
技術的なお話は、めちゃくちゃ難しいのですが、興味のある方はこちらの記事がとても分かりやすいです。(前提条件としてアルゴリズムと数学的知識が必須)
で、これを技術的に理解することは私も含めて一般人では厳しいので、ざっくりとしたイメージだけで語ると以下のようになります。
・オプションの様に後付けで付加できる方法(使い勝手はTextual Inversionに近い)
・異なる複数のLoRAを組み合わせることが可能
つまり、凄くぶっちゃけちゃいますと
Textual InversionとDream Boothの良いとこ取り
がLoRAの強みだと思います。
なので私の理解だとこんな感じです。
これを技術的に、もうちょっとだけ詳しく語ると、以下のようになります。
※以下としあきdiffusion Wikiからの引用です
技術的にくわしく!
- Dream Booth
新しいコンセプトを理解できるまで、拡散モデル自体を微調整する。
モデルを直接学習対象に含めるため、再現性という点では最も優れる。
しかし、ストレージは非効率(新しいモデルを扱う必要がある)- Textual Inversion
新しい概念を理解するための特別な単語を作成する。
出力は小さな埋め込み- LoRA
拡散モデルにわずかな重みを追加し、変更されたモデルが概念を理解するまでそれらを訓練する
拡散モデルではなく、それに対する重みを学習する。- Hyper Network
二次的なネットワークを使って、元のネットワークの新しい重みを予測する。LoRAの特徴として短い所要時間とDream Boothほどの時間が不要。
Dream Boothより再現性は一歩劣るものの、データ容量&VRAM消費というメリットが上回る。
特に2023年時点の市場ニーズにマッチしていて、導入しやすい。
主流GPUのVRAM量(約6~12GBが主流)や回線速度の事情(学習モデル配布における)。

画像生成技術を追うには、とても良いサイトなので、ご興味があればチェックしておくことをお勧め致しますよ。
私の様に雰囲気で楽しんでいるレベルとは比べ物にならない程高みにいる方々の集まりなのです。
ちなみに、今現在においてもLoRAの学習には「Kohya_ss」が良く使われています。
ですが、こちらのセッティングは、やや難解であるため、一般的なレベルではないと私は判断して今まで取り上げてませんでした。
しかし、技術革新は止まりません。
遂に、Stable Diffusion web UI(AUTOMATIC1111版)で簡単にLoRA学習ができる環境がやってきました。
それが後述する「Train Train」になります。
〇 TrainTrain
では、実際にその技術の凄さを目の当たりにして貰いましょう。
いやぁ、凄いのよ、本当に。
《注意》絵師(権利者)さんの絵を許可なく使うのはやめましょう
前の記事でも書いたことですが、再度引用した上で簡単に追記しつつ注意喚起しておきます。
特に、この手の話は敏感な方も多いでしょうし、ちゃんと私の立ち位置を明確にしておかないと、色々と大変な事になりそうですし。
このトレーニングを行うには、当たり前ですがAIちゃんにその概念を教える教材が必要です。
そして周りを見渡せば、魅力的な絵を描いて下さる絵師さんの存在が数多くあります。
ここに来て下さっている方の多くは、そんな魅力的な絵を見て、こんな風な絵をもっと見てみたいと言う憧れから、この技術を求めて来た方も多いのではないでしょうか?
だからこそ、絵師さんへの敬意を忘れないようにして欲しいです。
そもそも、この技術の発展は、絵師さんの存在なしにはあり得ません。
私は共存共栄していく形で発展していってほしいと願っております。
ですが現実には技術革新の速度が凄すぎて、法整備や意識の改革が遅れたまま、あまつさえこの技術を使えること自体を自分の特権と勘違いしてしまう方が一定数見受けられることがあって、それはもう荒れています。
私個人としても、実に悲しい事態です。
そもそも悪用している人を断ずるのは仕方ないと思うのです。
一方で私は、AIの存在そのものを禁止しようという姿勢には反対の立場です。
今あるものを無かった事には出来ませんので、どう上手く付きあっていくかが本当の課題だと私は考えます。
しかし、だから絵師さんの権利をないがしろにしていいかと言えば、そんなわけがないです。
ちゃんと絵師さんの権利を尊重しつつ、技術も発展していける環境が理想なのです。
そして、何が問題になっているのかと言えば、私は以下の点では無いかと思っています。
① そもそも大本となるモデルについて権利の透明性が担保されてない点
② LoRAなどで許諾していない絵師様の絵が勝手に使われている点
①については、仕組みづくりや法整備の問題になるので、その結果を待つしかありません。
なので、私のように使う側としても、その危険性を認識しつつ使いたいものです。
今回ご紹介するモデルにつきましても、権利の透明性が担保されておりません。
なので現時点においては商用にするのは論外であると同時に、生成した画像が自分の作品であると言い切れない事態になる可能性も視野に入れて行動した方が良いでしょう。
ただ、今後権利フリーのモデルが出てくれば、そのモデルを使って画像生成をする事自体に問題はなくなると思いますので、その時期が来るのを待つのも手でしょう。
②については、利用者の意識や認識の方がより重要かなと思います。
基本的にこちらは、同人活動と同じレベルの対応が必要かなと私は感じています。
つまり、権利者の方のご意向に寄与するところが大きいので、逆にこちらから権利者の皆様に迷惑になる行動は慎む必要があるという事です。
良く聞く話の一例としてあげますが、LoRAを使って絵師様の画像をそのまま作ってしまい、自分の作品として世に出してしまったり、あまつさえ商売にしてしまう事は論外です。
あくまで権利は絵師様にあるのです。
ただ一定数の権利者の皆様は、その作品が貶められるような事にならなければ、基本的に見逃してくれています。
それでも一部、絶対ダメ!という事もあるので、それはちゃんと権利元が発信してくれている意見を確認しましょう。
ただ、こう書くと直接権利者側に問い合わせる人が出てくるのですが、それは絶対にダメです。
冷静に考えて欲しいのですが「あなたの絵を私の好きなように使っていいですか?金儲けもしたいんでですけど?」と聞いて、「良いよ!」という方は、ほぼいません。
いたとしたら、それは凄く稀有な例であり、仏です。人を超越してます、多分。
あくまで、権利者の方に不利益にならない形でこっそりと楽しむ分においては「まぁ、見ないことにしてあげよう」となるのが話の本質なのです。
権利者の方も、真っ向から聞かれてしまったら「ダメです」としか言えないんです。
だから、逆に言えば「やめてください」と怒られたら、素直にごめんなさいして二度としないというのが、対応として取りえるものです。
絵師さんの絵はその絵師さんのものです。それは当たり前なのです。
なので私たちは最初に申し上げた通り、権利者の方に迷惑にならない形で、こっそりと楽しみましょう。
例えば、私は、過去からこの記事では一貫してウマ娘のハルウララの画像を出しています。
そしてウマ娘の明確な規約として、キャラクター(馬)のイメージを損なう表現は行わない事というものがあります。
※以下公式からの引用です
「ウマ娘 プリティーダービー」の二次創作のガイドライン
「ウマ娘 プリティーダービー」の二次創作のガイドラインについてご案内いたします。
本作品は実在する競走馬をモチーフとしたキャラクターが数多く登場しており、馬名をお借りしている馬主の皆様を含め、たくさんの方々の協力により実現しております。
モチーフとなる競走馬のファンの皆様や馬主の皆様、および関係者の方々が不快に思われる表現、ならびに競走馬またはキャラクターのイメージを著しく損なう表現は行わないようお願いいたします。
具体的には「ウマ娘 プリティーダービー」において、以下の条項に当てはまる創作物の公開はご遠慮ください。
- 本作品、または第三者の考え方や名誉などを害する目的のもの
- 暴力的・グロテスクなもの、または性的描写を含むもの
- 特定の政治・宗教・信条を過度に支援する、または貶めるもの
- 反社会的な表現のもの
- 第三者の権利を侵害しているもの
本ガイドラインは馬名の管理会社様との協議のうえ制定しております。
上記に当てはまる場合、やむを得ず法的措置を検討する場合もございます。
本ガイドラインは『ウマ娘』を応援していただいている皆様のファン活動自体を否定するものではございません。
皆様に安心してファン活動を行っていただけるよう、ガイドラインを制定しておりますので、ご理解ご協力のほどよろしくお願いいたします。
また、本ガイドラインに関するお問い合わせには、個別でのお答えはいたしませんのでご了承ください。
ウマ娘プロジェクトは名馬たちの尊厳を損なわないために、今後も皆様とともに競走馬やその活躍を応援してまいります。
その為、ウマ娘は性的な描写や暴力的な描写も含めて明確に禁止されているわけです。
私もウマ娘のコンテンツやハルウララが好きなので、これらの規約を認識して、その上で画像を出力しています。
この記事をお読みいただいている皆様も、今一度、その点に関して留意いただければと思います。
ちなみに、現時点において、この記事はそこまで権利を侵害するようなものになっていないと考えておりますが、再三申し上げております通り、運営さんからお咎めを頂いた場合は、お詫びするとともに速やかに対処します。
兎にも角にも、権利者様に見逃して下さっているという意識が、こと同人業界の認識としては重要ですので、この考え方を根底にしつつ、画像生成を楽しみましょう。
一方で私は、この技術は絵師さんにこそ使って欲しいと思っているのは、ずっと一貫して話してきたことです。
今の話の通り、自分が権利を持つ作品を読み込ませることについては、問題はありませんので。
そしてこの技術を使う事はこれからの必須条件となっていくでしょう。
私の意見に関わらずAIの発展は止まらないですし、今もそうなっているからです。
今回は省略しますが、今のレベルなら実用レベルに限りなく近いです。
線画を元に絵を描いたり、逆に絵から線画を抽出する事も可能なレベルになってます。
まだ、個々の機能が出てきた段階ですが、これが統合されて一つの環境に集約されれば、一大ツールとして活用される日は、そう遠くないでしょう。
今までの絵師さんの苦労は、それはもう私ごときでは計り知れないほど、大変であろうことは容易に想像ができます。
その苦労の一端を、AIの技術で肩代わりできるはずだと、私は今もなお信じております。
ちなみにどれだけAIが進歩しても、絵を描ける人の方が、私のような絵を描けない人に比べてはるかに有利なのはこれからも変わらないでしょう。
何故なら私は、ちょっとだけ手を入れての修正すらできませんが、絵心のある方は、それが可能です。
神絵師達と皆様の差は凄く埋まるでしょうが、私のような絵心の無い人と、少しでも絵が描ける人の差は変わらないと思います。
それは絵の描ける人がこの技術を使ってみない事には理解できないでしょう。
使ってみれば、絵師さんが使う事で見えてくる優位な部分も沢山あると思います。
AIの出来る事、できないこと。導入の苦労や使いこなす難易度の高さ。
そう言ったもの全てを踏まえた上で、どうやってAIと向き合っていくかを考える指標になってくれればと思います。
Train TrainでLoRAをトレーニングしてみよう!
前置きが長くなりましたが、とてつもなく大事な事だったので。
では、例の如く私のPC環境をある程度こちらに記載しておきたいと思います。
・CPU
Core i7-12700

・OS
Windows 11
・メモリ
48G
・私の知識レベル
Java ScriptやGASなら書けるくらい
Python?最近流行ってるよねーくらい
開発環境? 何それ美味しいの?(テキストベタ打ち)
しかし私の予想通り、3060は、めちゃくちゃ人気ですね。
まぁ、コスパの塊だからさもありなん。
そして、今回も結論から申し上げますと、3060(12G)でなら、何の問題もなくトレーニングできてます。
ああ、メモリーオーバーフローのエラーが出ないって素晴らしい(ぁ
また、これから基本事項を抑えつつ、一つづつ解説していきますが、ぶっちゃけ今は動画が沢山出ています。
私も手順は、こちらの動画を参考に致しました。
もし動画の方が良いという方は、こちらの方の動画をお勧めします。
大抵の方は、これで上手く行くでしょう。
ただし、少し時間が経っていることから、一部作業で違う点がありましたので、一応残しておきます。
① TrainTrainのインストールでエラーが発生し、web UIが起動しなくなった。
→ 下の記事で私の対処法を紹介しています。
② トレーニングフォルダを設定する際にエラーが出た。
→ 動画ではトレーニングフォルダの上のフォルダを設定していましたが、私の場合は直接そのフォルダを設定する必要がありました。
以上、相違点を踏まえて動画も参考にしてみて下さい。
再度確認 Stable Diffusion web UIのインストール方法
さて、割とStable Diffusion web UIのインストールで躓く方が多いっぽいようで、そのような方もこちらのサイトをシレっと見て下さっているようです。
確かに、コマンドプロンプトに慣れていない方は、このインストール時点でめっちゃ躓きそうです。
最近は、他のサイトでもインストール方法を紹介している記事が増えてきた印象です。
なのでこちらでは、そう言った記事のご紹介と、簡単な設定方法だけ再度、書いておきたいと思います。
まず、うちの超見ずらい(自覚はある)サイトよりは、とても良い記事がありました。
モデルの紹介もありますので、基本はこちらのサイトで見ていけばいいかと思います。
では、その上で一応、こちらのサイトでも軽く書いておきますね。
とりあえず、注意点としては前の記事から変わらず、以下の部分です。
① Pythonは3.10.9を使いましょう
実は新しいバージョンで3.11.0が来てるのですけど、そちらだと上手く動きませんでした。
多分、ソースでバージョンを縛る部分があるっぽいです。
なので、3.10.9を選んでインストールしましょうね。
ちなみに前回の記事では3.10.8で紹介していましたが、バージョンが上がっていたので一応、こちらに差し替えてます。
とりあえず問題なく動いているっぽいので、どちらでも良いかなーとは思います。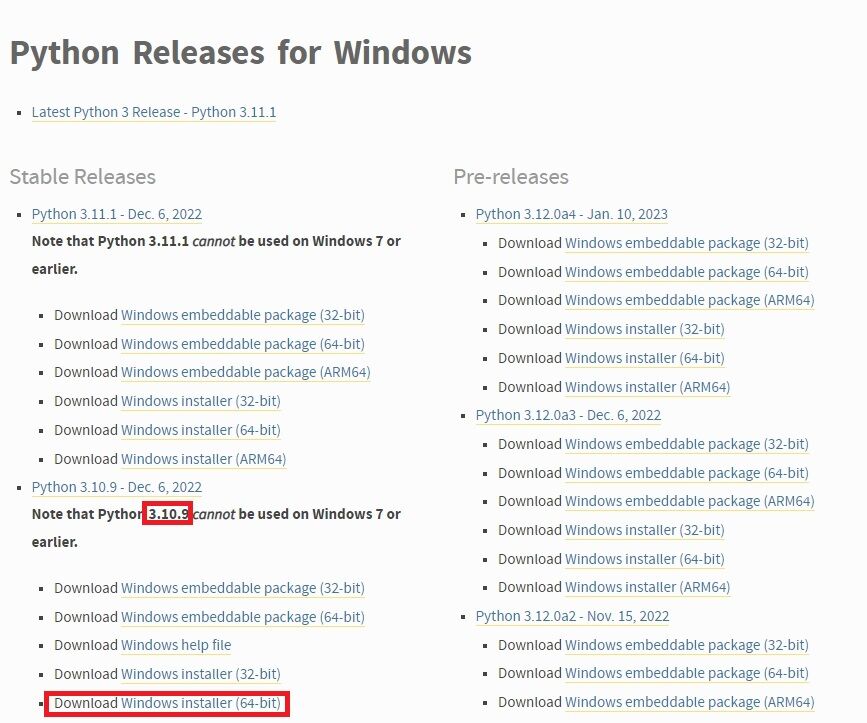
〇 Download Windows installer (64-bit)
インストールの際には、下部の「Add Python 3.10 to PATH」にチェックを入れる事をお忘れなく。
最悪間違ったらアンインストールからの再インストールでもOKです。
② Git は最新のものでOK CUDAは必要なし
逆にGitは、最新のものでOKです。
前回の記事ではCUDAも入れるようにご案内しておりましたが、どうやらWebUI側で対応したらしく、PCへ個別に入れる必要はなくなりました。
上手くインストールできたか確認したい場合は、コマンドプロンプトで以下のコマンドを使ってみましょう。
コマンドプロンプトの起動方法が分からないという方は、以下のサイトを参考にしてみて下さいね。
簡単に説明すると「Windows(四つの🔲が集まったマーク)」+Rで「ファイル名を指定して実行」を開き、「cmd」と入力します。
〇 Ptythonのバージョン
python -V※注 Vは大文字
なおコマンドをこちらでコピーしたら、コマンドプロンプト上で右クリックすることでペーストできます。
なお、コマンドプロンプト上の文字をなぞって色を付け右クリックをすると、その文字列をコピーできます。
貼り付けた後、エンターキーで、コマンドを実行できますので、覚えておきましょう。
〇 nvccのバージョン
nvcc -V〇 gitのバージョン
git --version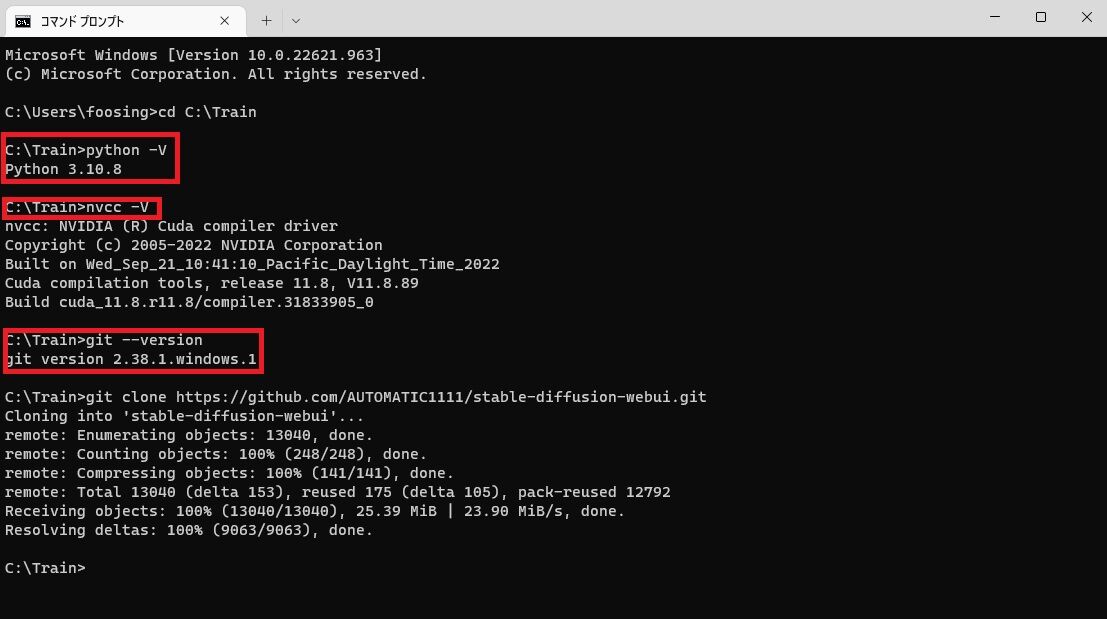
① Stable Diffusion web UI(AUTOMATIC1111版)をインストール
まずはStable Diffusion web UI(AUTOMATIC1111版)をインストールするのですが、実は今はめちゃくちゃ楽です。
まず、インストールするフォルダを作っておきましょう。
今回はCドライブ直下にlora(える・おー・あーる・えー=ローラ)というフォルダを作りました。
C:\lora
コマンドプロンプトを起動し、その場所に移動します。
cd C:\loracd(スペース)ファイルアドレス
前の記事で書いたように、エクスプローラー上でファイルの場所を右クリックして「アドレスをテキストとしてコピー」をした後、コマンドプロンプト上で右クリックするとその場所を貼り付けられます。
cd を前に書いてファイルパスを貼り付けたあと、エンターキーを押しましょう。
C:\lora>
※ファイルの場所
となっていたら準備OKです。
以下のコマンドをコピーして貼り付けエンターキーを押します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webuiインストールが始まり、lora(指定したフォルダ)内に「stable-diffusion-webui」フォルダが作成されているはずです。
② モデルの配置
その後は、モデルを配置します。
C:\lora\stable-diffusion-webui\models\Stable-diffusion
上記のフォルダにモデルを入れておきます。
今回は「Animagine XL 3.1」を置いておきました。
「Files」タブから「animagine-xl-3.1.safetensors」をダウンロードしましょう。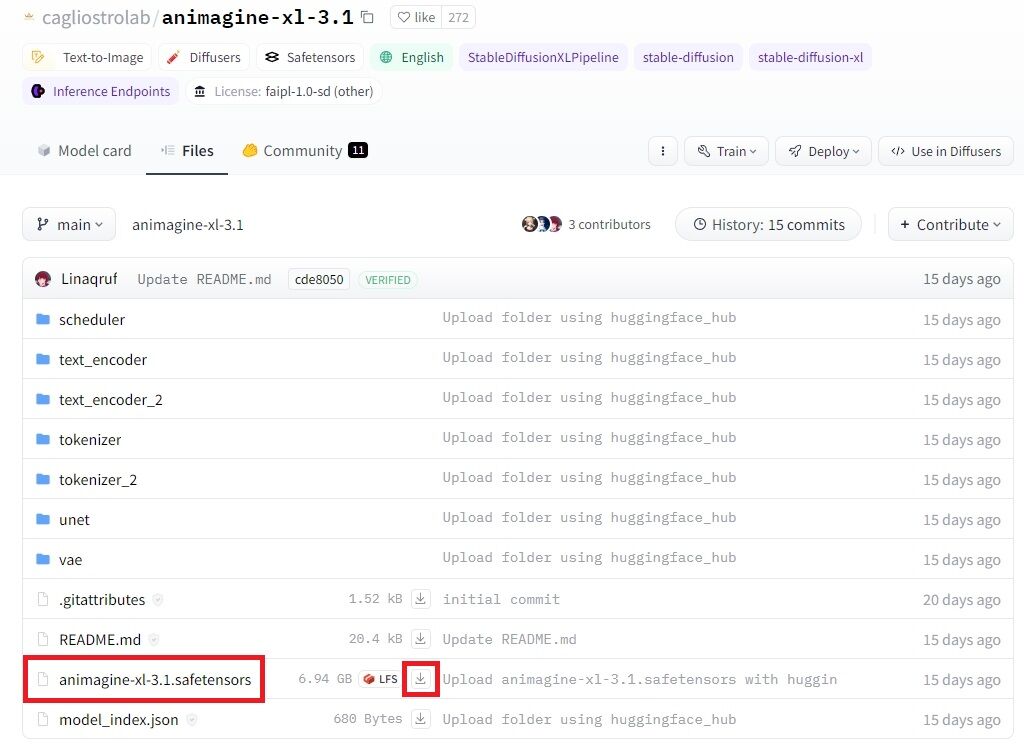
このモデルは、アニメ描写に強いモデルで、かなり完成度が高いのです。
公式にもありますが、ネガティブプロンプトには、以下の物を使いましょう。
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
通常プロンプトに、以下の物を使うと、精度が上がるようです。
masterpiece, best quality, very aesthetic, absurdres
また、こちらのモデルはVAE込みなので、VAEは使わない方が良いとの事です。
もし、昔から画像生成を楽しまれている方は注意して下さいね。
一つ注意点として、このモデルはアニメの絵を使っている可能性が高いので今後の版権に関して問題がある可能性も含んでおります。
くれぐれもご利用は、慎重にお願いします。
③ webui-user.batから起動する
なお、トレーニングするにあたって起動batである「webui-user.bat」内の「COMMANDLINE_ARGS」に以下の設定をしておきましょう。
「stable-diffusion-webui」フォルダ内の下の方に「webui-user.bat」というファイルがあると思います。
グラボのメモリが低い場合は、「xformers」の導入が必要です。
ただしRTX3060レベル以上のグラボであれば、今は必要ありません。
必要ない方は、そのまま「webui-user.bat」をダブルクリックして起動します。
「xformers」の導入が必要な方は、右クリックで編集を選択し、メモ帳などで開きます。
Windows11は編集が隠れておりますので、Shiftキーを押しながら右クリックをしましょう。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers
git pull
call webui.bat
ちなみに「git pull」を入れておくと「webui-user.bat」で起動した際に、更新をかけてくれるようになります。
最新状態にしておきたい方で、私のようなものぐさな人は入れておきましょう。
逆に、環境をなるべく変えたくない人は入れないでおきましょう。
※「xformers」の導入スキップした方はここから
「webui-user.bat」をダブルクリックして起動します。
トレーニングする場合の起動は「webui.bat」ではなく「webui-user.bat」ですのでお間違いないように。
起動すると新しいコマンドプロンプトが立ち上がり、暫く固まります。
見た目には動きが少ないので心配になりますが、そのまま根気強く待ちましょう。
最後の方に「http://127.0.0.1:7860」等のリンクが出て自動でブラウザが立ち上がればOKです。
ブラウザが自動で開かない人は、コマンドプロンプト上のリンクを「ctr」を押しながらクリックすれば、すぐに開くと思います。
仮にエラーが出て止まった場合、大抵の場合はモデルの配置忘れです。
正しい場所にモデルが配置されているか、確認しましょう。
これにて基本構成の構築は終了です。
ただ使うだけならばこれで十分なので、使いたいだけの方は参考にしてみて下さいな。
Stable Diffusion web UI(AUTOMATIC1111版)へDataset Tag Editorを導入する方法
さて、早速……と行きたいのですが、その前にまず下準備が必要です。
LoRAでトレーニングするには、その教材となる絵を用意しトレーニング用に加工する必要があります。
その加工に便利なツールとして、今回はDataset Tag Editorをご紹介します。
まずはStable Diffusion web UI(AUTOMATIC1111版)へDataset Tag Editorを導入する方法を解説します。
〇 Dataset Tag Editor
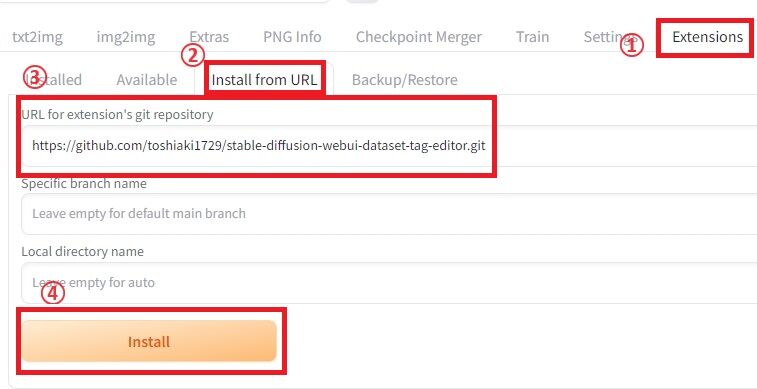
①「Extention」タブにある
②「Install from URL」の
③「URL for extension’s git repository」に以下のURLをコピーして
④「Install」ボタンを押します。
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git
インストールが完了しましたら、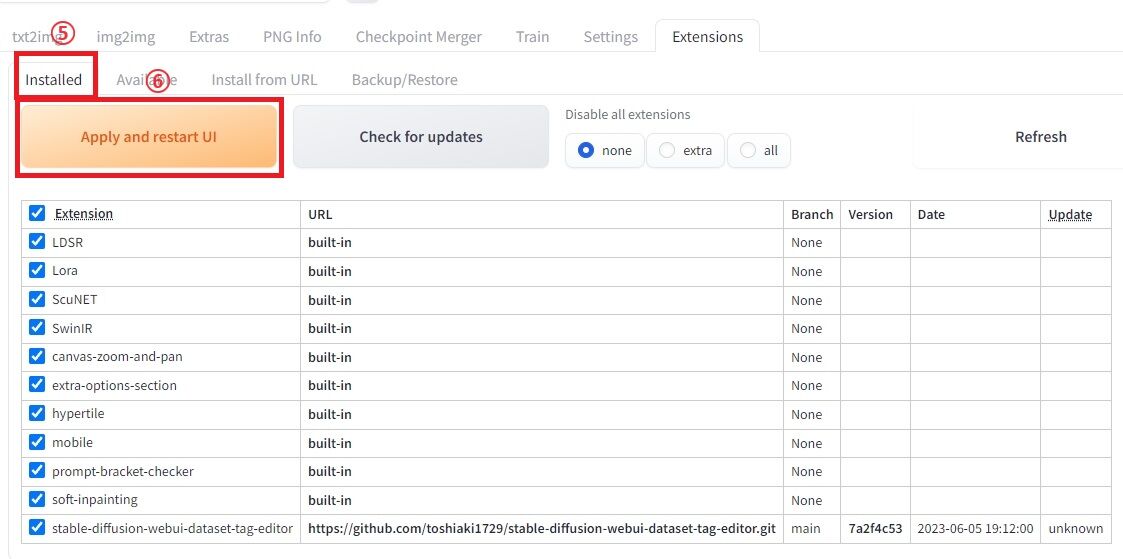
⑤「Installed」タブの
⑥「Apply and restart UI」ボタンをクリックして再起動します。
以上で、Dataset Tag Editorの導入は完了です。
Stable Diffusion web UI(AUTOMATIC1111版)へTrainTrainを導入する方法
ここからが本番ですね。
Stable Diffusion web UI(AUTOMATIC1111版)へTrain Trainを導入する方法を解説します。
〇 TrainTrain
「Extention」タブにある「Install from URL」の「URL for extension’s git repository」に以下のURLをコピーして「Install」ボタンを押します(Dataset Tag Editorの時と全く同じ)
https://github.com/hako-mikan/sd-webui-traintrain.git
暫くしたら、Dataset Tag Editorの時と同様に、「Installed」タブの「Apply and restart UI」ボタンをクリックして再起動します。
※ もし、エラーが出てWebUIが立ち上がらなくなったら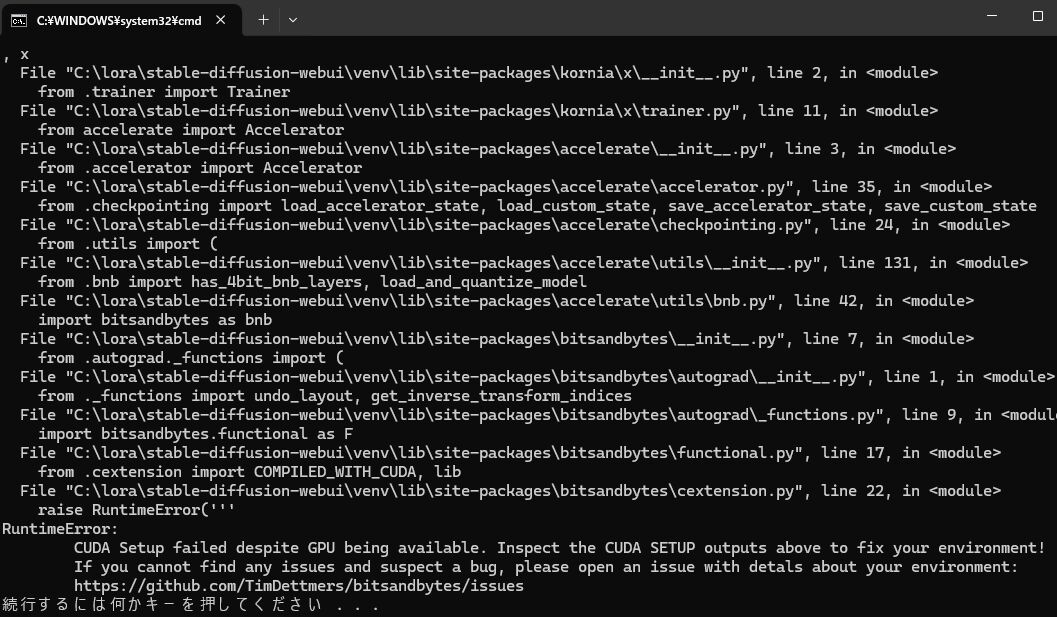
私の環境では、traintrainをインストールをすると、以下の様なエラーが出てWebUIが起動しなくなります。
※以下エラーメッセージです
===================================BUG REPORT===================================Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues================================================================================binary_path: C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dllCUDA SETUP: Loading binary C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dll…Could not find module ‘C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dll’ (or one of its dependencies). Try using the full path with constructor syntax.CUDA SETUP: Loading binary C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dll…Could not find module ‘C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dll’ (or one of its dependencies). Try using the full path with constructor syntax.CUDA SETUP: Loading binary C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dll…Could not find module ‘C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cuda_setup\libbitsandbytes_cuda116.dll’ (or one of its dependencies). Try using the full path with constructor syntax.CUDA SETUP: Problem: The main issue seems to be that the main CUDA library was not detected.CUDA SETUP: Solution 1): Your paths are probably not up-to-date. You can update them via: sudo ldconfig.CUDA SETUP: Solution 2): If you do not have sudo rights, you can do the following:CUDA SETUP: Solution 2a): Find the cuda library via: find / -name libcuda.so 2>/dev/nullCUDA SETUP: Solution 2b): Once the library is found add it to the LD_LIBRARY_PATH: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:FOUND_PATH_FROM_2aCUDA SETUP: Solution 2c): For a permanent solution add the export from 2b into your .bashrc file, located at ~/.bashrcTraceback (most recent call last):File “C:\lora\stable-diffusion-webui\launch.py”, line 48, in <module>main()File “C:\lora\stable-diffusion-webui\launch.py”, line 44, in mainstart()File “C:\lora\stable-diffusion-webui\modules\launch_utils.py”, line 465, in startimport webuiFile “C:\lora\stable-diffusion-webui\webui.py”, line 13, in <module>initialize.imports()File “C:\lora\stable-diffusion-webui\modules\initialize.py”, line 26, in importsfrom modules import paths, timer, import_hook, errors # noqa: F401File “C:\lora\stable-diffusion-webui\modules\paths.py”, line 60, in <module>import sgm # noqa: F401File “C:\lora\stable-diffusion-webui\repositories\generative-models\sgm\__init__.py”, line 1, in <module>from .models import AutoencodingEngine, DiffusionEngineFile “C:\lora\stable-diffusion-webui\repositories\generative-models\sgm\models\__init__.py”, line 1, in <module>from .autoencoder import AutoencodingEngineFile “C:\lora\stable-diffusion-webui\repositories\generative-models\sgm\models\autoencoder.py”, line 12, in <module>from ..modules.diffusionmodules.model import Decoder, EncoderFile “C:\lora\stable-diffusion-webui\repositories\generative-models\sgm\modules\__init__.py”, line 1, in <module>from .encoders.modules import GeneralConditionerFile “C:\lora\stable-diffusion-webui\repositories\generative-models\sgm\modules\encoders\modules.py”, line 5, in <module>import korniaFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\kornia\__init__.py”, line 11, in <module>from . import augmentation, color, contrib, core, enhance, feature, io, losses, metrics, morphology, tracking, utils, xFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\kornia\x\__init__.py”, line 2, in <module>from .trainer import TrainerFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\kornia\x\trainer.py”, line 11, in <module>from accelerate import AcceleratorFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\accelerate\__init__.py”, line 3, in <module>from .accelerator import AcceleratorFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\accelerate\accelerator.py”, line 35, in <module>from .checkpointing import load_accelerator_state, load_custom_state, save_accelerator_state, save_custom_stateFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\accelerate\checkpointing.py”, line 24, in <module>from .utils import (File “C:\lora\stable-diffusion-webui\venv\lib\site-packages\accelerate\utils\__init__.py”, line 131, in <module>from .bnb import has_4bit_bnb_layers, load_and_quantize_modelFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\accelerate\utils\bnb.py”, line 42, in <module>import bitsandbytes as bnbFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\__init__.py”, line 7, in <module>from .autograd._functions import (File “C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\autograd\__init__.py”, line 1, in <module>from ._functions import undo_layout, get_inverse_transform_indicesFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\autograd\_functions.py”, line 9, in <module>import bitsandbytes.functional as FFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\functional.py”, line 17, in <module>from .cextension import COMPILED_WITH_CUDA, libFile “C:\lora\stable-diffusion-webui\venv\lib\site-packages\bitsandbytes\cextension.py”, line 22, in <module>raise RuntimeError(”’RuntimeError:CUDA Setup failed despite GPU being available. Inspect the CUDA SETUP outputs above to fix your environment!If you cannot find any issues and suspect a bug, please open an issue with detals about your environment:https://github.com/TimDettmers/bitsandbytes/issues続行するには何かキーを押してください . . .
エラーを読むに、venv内にある「bitsandbytes」が悪さをしているようです。
少し調べてみたところ、以下のような記事を見つけました。
なるほど、他の環境とはいえ、似たような現象ですね。
恐らくですが、venv内の「bitsandbytes」を強制的に書き換える必要がありそうです。
なので、ここからは自分流のやり方の為、責任は持てません。
もし、参考になさる場合は、この作業はバックアップを取ったうえで、最悪消えてもいい環境で行いましょう。
コマンドプロンプトを起動して、以下のコマンドでディレクトリを移動し、コマンドでvenv内の「bitsandbytes」をアンインストール→再インストールします。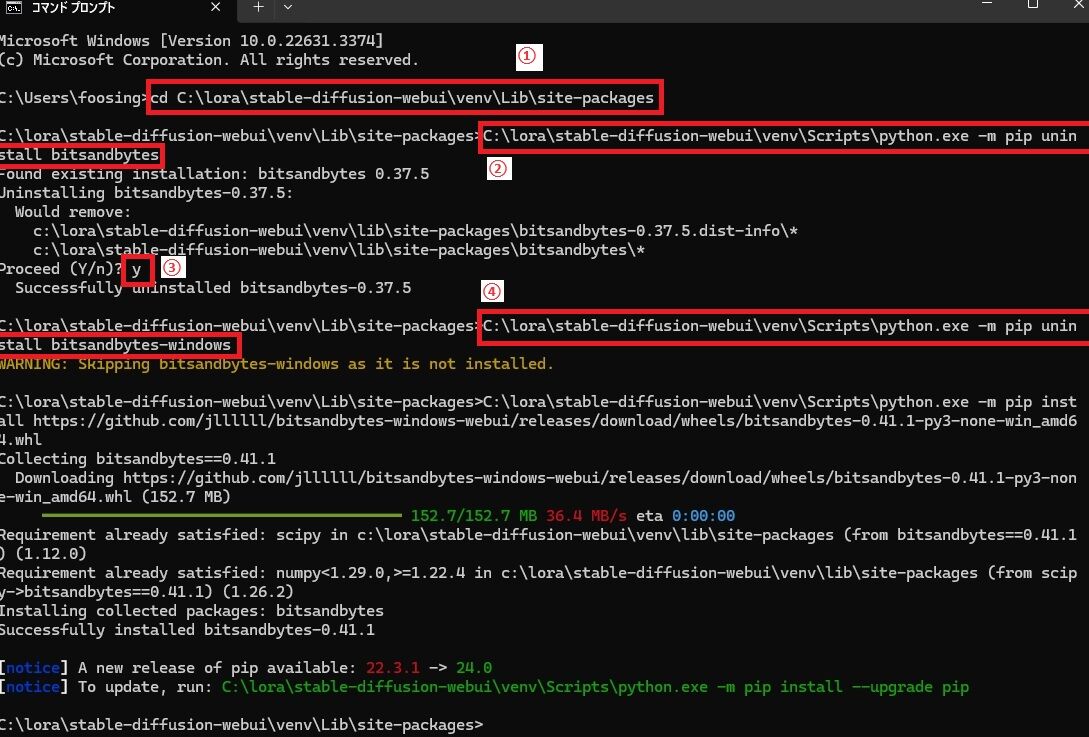
① ディレクトリの移動
cd C:\lora\stable-diffusion-webui\venv\Lib\site-packages
「bitsandbytes」は、上記のパスにありますので、こちらに移動します。
② bitsandbytesの削除
C:\lora\stable-diffusion-webui\venv\Scripts\python.exe -m pip uninstall bitsandbytes
こちらのコマンドを入力後、途中で本当に削除するか聞かれるので
③「y」を入力して続行します。
④ bitsandbytesの再インストール
C:\lora\stable-diffusion-webui\venv\Scripts\python.exe -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.1-py3-none-win_amd64.whl
こちらのコマンドを入力で再インストールします。
2分ほどで終わりますので、終わったら、コマンドプロンプトを閉じて、いつものように「webui-user.bat」をダブルクリックして起動します。
恐らくこれで問題なく立ち上がるようになると思います。
では、traintrainでトレーニングしましょう
と言う訳で、長々と語りましたがやっと本番です。
長くなりすぎてお忘れの方も多いと思いますので、再度、釘を刺しておきますが、
許可の取れていない絵師さんの絵でトレーニングするのはやめましょう。
と、ここまで口を酸っぱくして言ったのと、ここに来るオタクの皆様は基本的に紳士淑女(意味深)なので、信じております。
あ、まず、再度、前回の記事同様に最初に宣言しておきますが、
私は、今までお世話になった絵師様の絵を勝手に使ってトレーニングしないと誓います
じゃあ、何を使うんだ?と言う話ですが、前回と同じハルウララで行きましょう。
と言うか、その為にAIちゃんをいじってるだけなので。
とりあえず、現時点においても運営さんから怒られてませんので、静かに楽しみたいと思います。
もし怒られたら土下座してすぐに消します、はい。
ちなみに、私は怒られてないから何でもヒャッハーして良いとは微塵も思ってません(超大事)
あくまで私の楽しめる範囲でひっそりと、色々と楽しんでいる訳です。
しかし、本当にウララ可愛いのぉ……(しみじみ
愛するキャラであるが故に、権利者の皆様の不利益になるような使い方だけはしないように気をつけたいですね!
では、今回もやり方を追っていきましょう。
① 学習元になる画像ファイルを用意する
今回もウララの可愛い姿を集めました。
以前の記事でも触れましたが、画像ファイルの厳選はとても重要です。
特に以下の点にこだわって、自分が良いと思う画像を選びましょう。
・解像度がなるべく高い画像
・余計なものが無い画像(オブジェクトや文字関連)
・(可能であれば)背景を透過処理した画像
・自分の解釈に合う画像(後述)
さて、ここでちょっと、語りモードに入ります(唐突)
私は、今回もウララを学習させようとしている訳ですが……
そもそもハルウララとは、何なのでしょうか?(哲学)
これは以前の記事でも最後に触れたのですが、この考え方はこの先トレーニングをする上で割と重要なので、あえて取り上げたいと思います。
皆さまも、恐らく推しの素敵な姿を体現する為に、ここに来たと私は思っています。
であるならば余計に、推しの存在を定義することは、この先に進む上でとても大事な事なんです。
例えば、いつものハルウララがいます。可愛いですね。
これぞ彼女!と言う感じですし原点でもあるので、私は大好きです。
変わって私服ですけど、これはこれで可愛らしいですよね。
子供っぽさを良しとするかで評価が分かれそうですが。
そして、晴れ着のウララ! 素敵ですね!
どれもみんな違って可愛いですし、甲乙つけがたいのが私の偽らざる心境です。
さて、そこで、再度質問です。ウララとは、何でしょうか?
この様に、衣装が変わってもウララはウララです。
しかし、この先に進むには、この命題に自分なりの答えを出す必要が出てきます。
例えば「勝負服のウララ以外は、ウララじゃない!」と言う方がいらっしゃるとしましょう。
その場合は、他の衣装のウララをトレーニングに使うのは良くないです。
何となく私の言いたい事が、伝わったでしょうか?
私は先ほども語った通り、全部が全部ウララで可愛いという結論です。
なので全部の絵を使いますが、その中でウララをウララとして認識させる要素を抜き出す必要が出てきます。
例えば、上の3枚の絵のうち、2枚は耳当てと鉢巻をしています。
しかし、晴れ着ウララは片方の耳当てだけで、鉢巻がありません。
鉢巻をしていないウララは、ウララじゃない!!
そう感じる方は、鉢巻がウララの存在を定義するアイテムとして必要だと思っていることになります。
私は、どちらもウララだと思っているので、鉢巻は絶対的に必要なものではないと考えてます。
あ、誤解のないように申し上げておきますが、結論としてどちらでも良いんです。
私のウララ像は、そうだと言うだけで、それが正しいというつもりは微塵もありません。
鉢巻が無いとウララじゃないという気持ちもわかりますし、それで良いと思います。
と、何を読まされているんだ?私たちは?と思われる方が出てくる頃合いだと思いますので、まとめます。
つまり、自分の推しに絶対的に必要な特徴を選ぶことが後で必要になります。
これがブレていると、後の作業にも影響しますので、それだけは抑えておいてください。
以上、画像の選び方についてでした。
② 「Dataset Tag Editor」用フォルダを作る
ここがまず最初のポイントです。
最初に元になる画像を利用して、トレーニング環境を作ります。
まずトレーニング環境のベースとなるフォルダを作成します。
場所はどこでも大丈夫です。
ただ一つ注意点として、フォルダ名は後にプロンプトで呼び出す際に使用する単語にします。
私はハルウララを呼び出す語を「HaruUrara」と定義しているので、フォルダ名もそうします。
記号や空白が入ると失敗する可能性もありますので、可能な限り英字の羅列で設定しましょう。
そのフォルダ内に、先ほどトレーニング用に厳選した画像ファイルを格納します。
一応、ファイル名は単純に通し番号に設定します。
上記の様にフォルダ内に画像が揃ったら、web UI(AUTOMATIC1111版)を起動します。
③ 「Dataset Tag Editor」でトレーニング環境を作る
このタブは、トレーニング画像の参照場所や、トレーニングに必要なパラーメータを設定するところです。
では、以下に設定手順を説明していきます。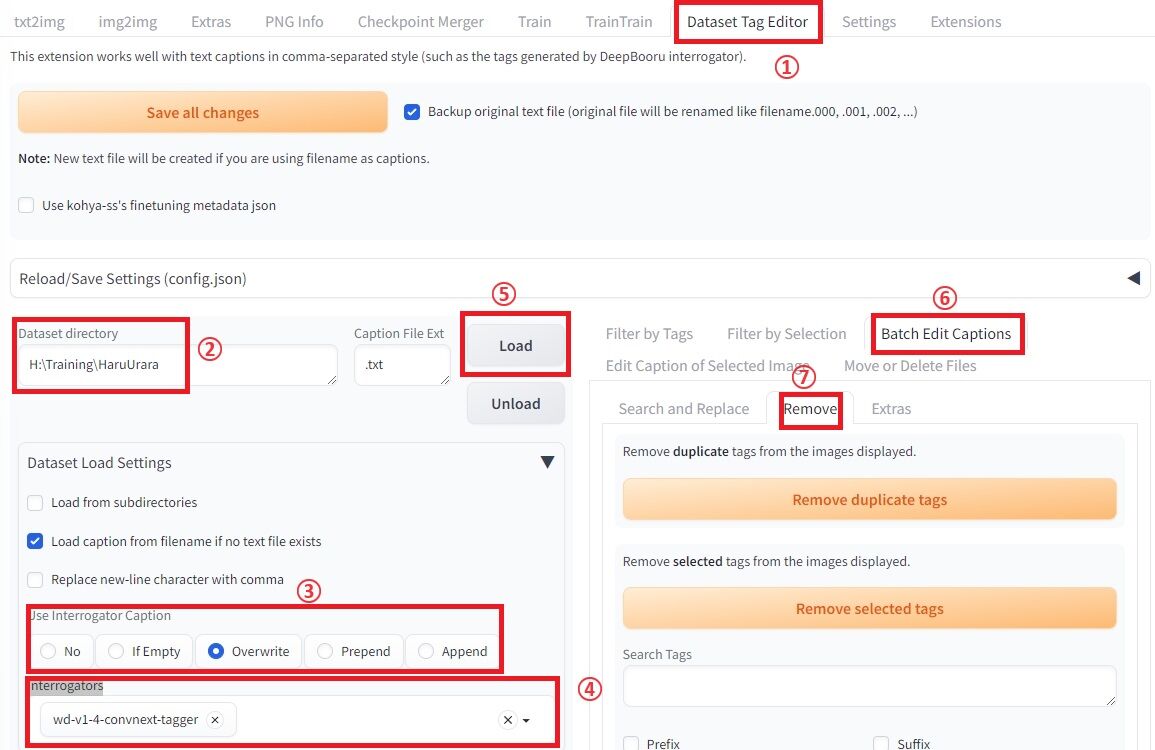
① Dataset Tag Editorタグを選択し、上記の画面を出します。
② Dataset directoryに、トレーニング用の画像が入ったフォルダのパスを入れます。
③ Use Interrogator Captionを選択します。
初回なら「if Empty」でも良いですが、2回目以降は「Overwrite」で上書きが必要です。
④ Interrogatorsを選択します。個人的には「wd-v1-4-xxx」系がおすすめです。
拾ってくれる語彙が多いと感じました。
⑤ Loadボタンを押して画像を読み込みます。
暫くすると、読み込みが完了し、作業が出来るようになります。
⑥ Batch Edit Captionsを選択します。
⑦ Removeを選択します。
その後、以下の作業が非常に重要になります。
画像の質以上に、明暗をくっきりと分けますが、気負わず進めていきましょう。
ここで、キャラの特徴を選んでいきます。
ポイントなのは、絶対に残したい特徴です。
例えば、今回の場合は、こんな感じに出てきます。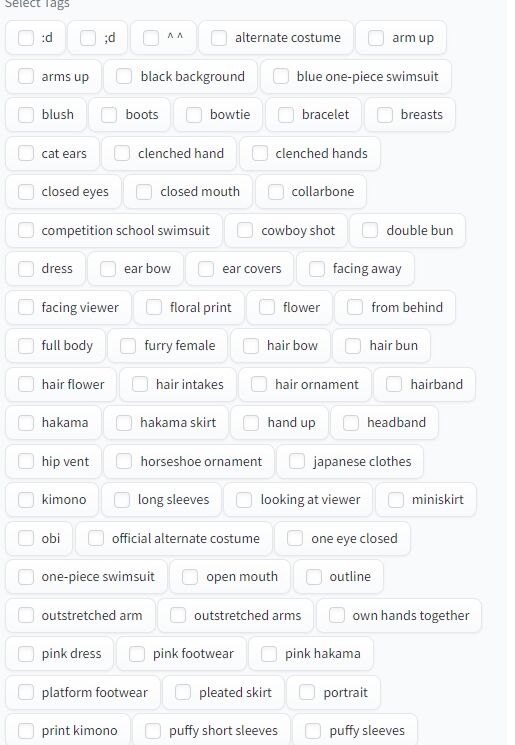
私の様に、英語アレルギーのある方は、これだけで挫けそうになると思いますが、ここが頑張りどころです。
そして、もしchromeブラウザを使っているなら、この作業は少しだけ簡単にできます。
URL&検索バーの右にこういうマークがあると思います。
基本的にはあるはずですが、chromeでなかったり、見当たらない場合は、拡張機能を入れてみましょう。
これで日本語化すれば、少しは楽に作業できると思います。
ただ、理想を言えば英単語のままの方がニュアンスが分かりやすいので、並行して単語も覚えていきましょう。
で、最終的に私はこうなりました。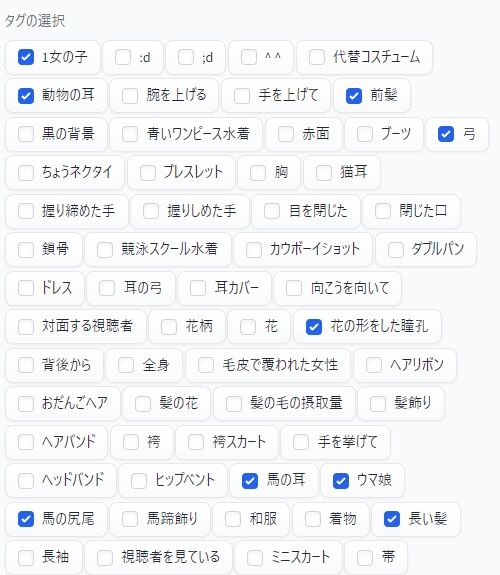
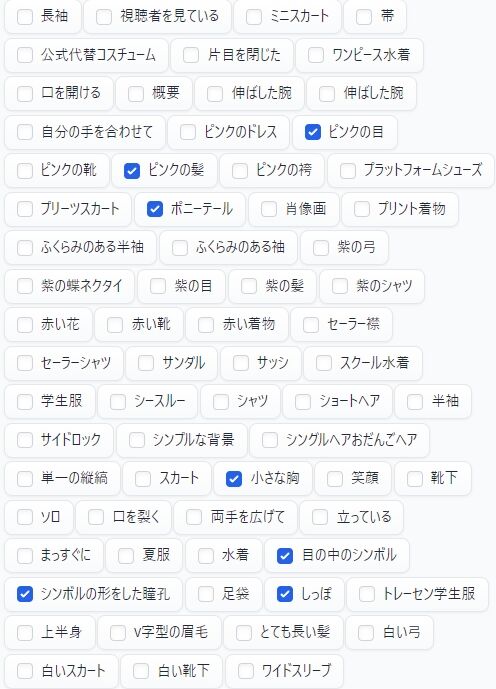
この記事を書いていて気づいてしまいましたが、この時は「とても長い髪」のチェックが漏れてますね。
本来であればチェックする必要のあるものでした。
この様に、ハルウララの特徴を表し、変化させたくないものを選びます。
例えば服装や構図などは、むしろドンドン変化させたいので、私は選びません。
先ほどの例で触れました鉢巻に関しても、外すのがデフォルトにしたいので、こちらもそういう形にしています。
ただ、ここで鉢巻を外したいと思って選んでおいたとしても、選んだ絵に鉢巻き姿が多いと、それに引っ張られる傾向があります。
この辺りのバランスも加味して、なるべく自分の目指す理想の形に整えた画像を厳選していきましょう。
タグを全て選び終わったら、後少しです。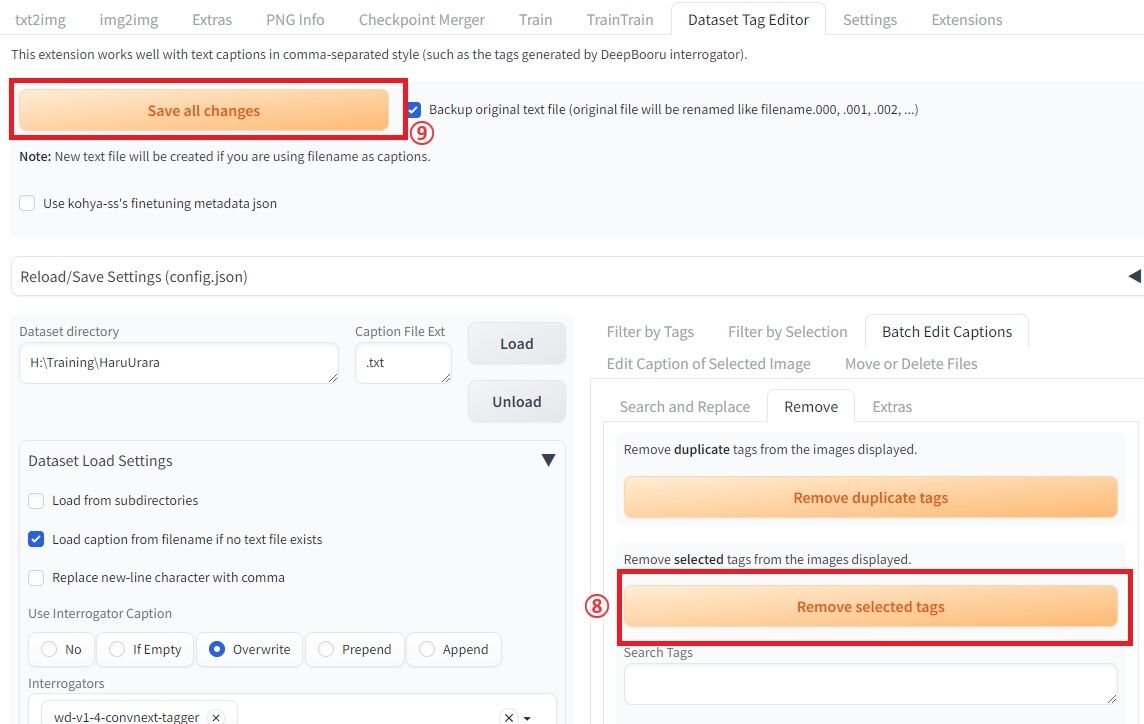
⑧ Remove selected tagsで、選んだタグを消します。
え?消しちゃうの?と思われる方もいらっしゃるかもですが、LoRAの仕組み上、差分をとるので、そうなるようです。
duplicateの方を選ばないように気をつけましょう。
⑨ Save all changesを選択します。
トレーニング用の画像が入ったフォルダにテキストファイルが追加されます。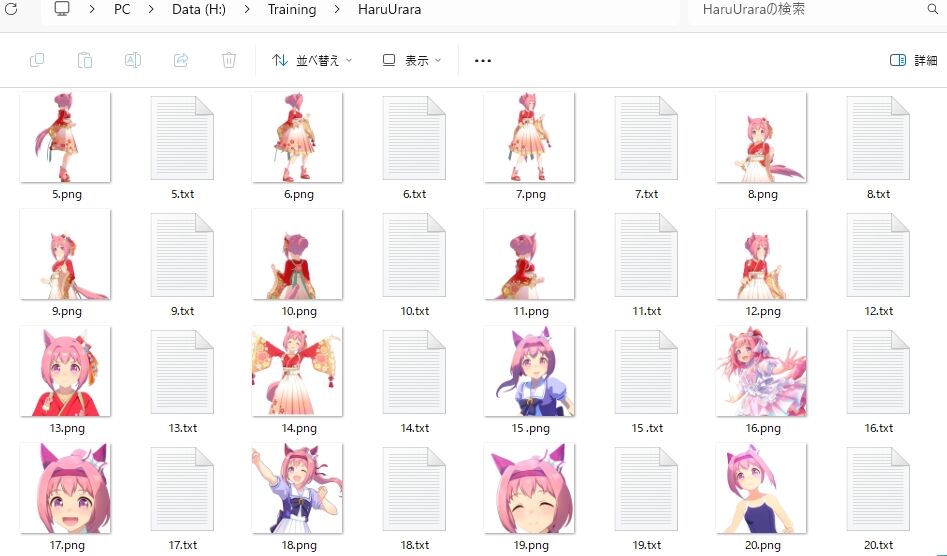
これで作業の完了です。
以前はもっと面倒だったのですが、今はここまで楽になりました。
本当に技術の進歩に感謝しかないです。
さぁ、後は、設定を行いトレーニングを開始するだけです。
④ TrainTrainタブからトレーニング開始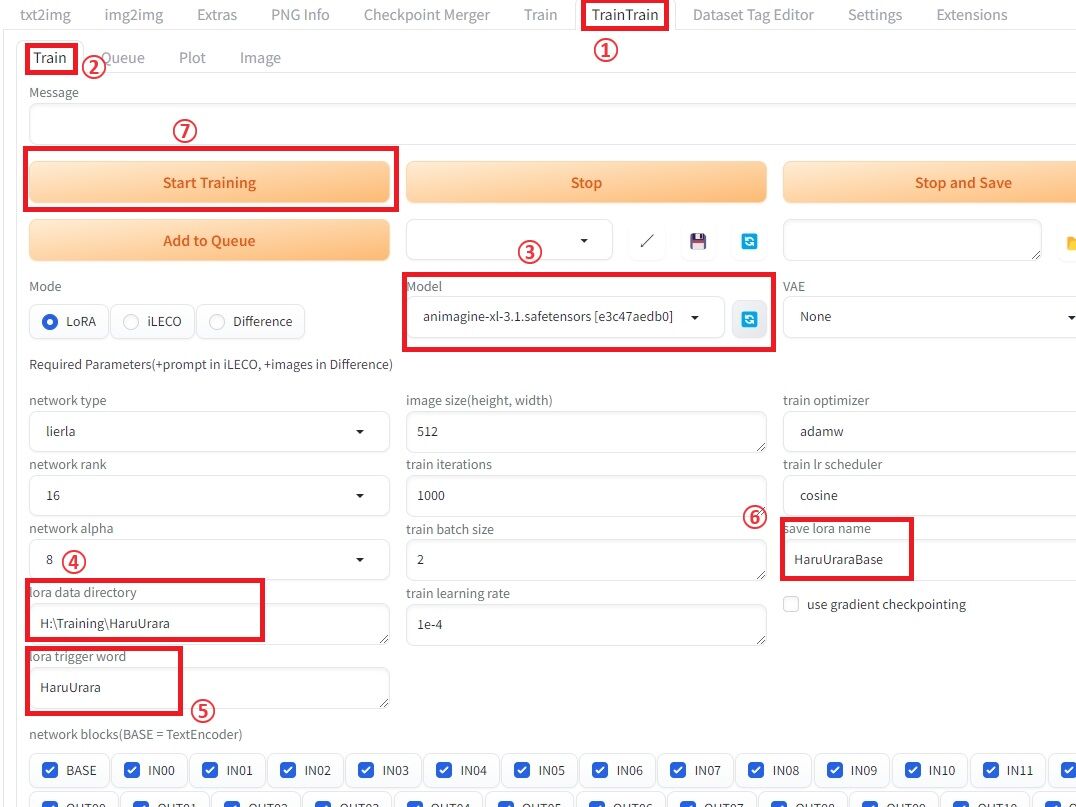
では早速、トレーニング設定を行いましょう。
とは言え、昔と比べて実はあまりやることがありません。
① TrainTrainタブを選択します。
② Trainタブを選択します(デフォルト)
③ モデルを選択します。
今回は、最初にご紹介した「Animagine XL 3.1」を使用します。
慣れてくると割と選び忘れるので注意しましょう。
④ lora data directoryに、画像とテキストファイルがセットになったフォルダのパスを追加します。
Dataset Tag Editorで作業したフォルダと同じものです。
⑤ lora trigger wordに、呼び出すプロンプトとして設定したい語を入力します。
この際、上記のフォルダ名と同じに揃えておきましょう。
⑥ save lora nameにLoRAファイル名を設定します。
設定しなくても問題はありませんが、その場合は「untitled」で作成されます。
⑦ Start Trainingをクリックしてトレーニングを開始
たったこれだけです。
私の場合、設定をいじる必要はありませんでした。
※「RuntimeError」が出る場合
トレーニングを開始すると、何故かこんなエラーが出ました。
RuntimeError: permute(sparse_coo): number of dimensions in the tensor input does not match the length of the desired ordering of dimensions i.e. input.dim() = x is not equal to len(dims) = x”
少し調べてみて分かったのは、どうやら見れない値を参照していそうだという事です。
結論から申し上げますと、フォルダの参照値がおかしかったようです。
今回の作業では、フォルダを参照しているのは、lora data directoryに、画像とテキストファイルがセットになったフォルダのパスを入れるときだけです。
なので、画像とテキストファイルが入っているフォルダーを直で指定したら出なくなりました。
もしエラーが出たらフォルダのパス、構成や名前を含めて、参照する数値が間違っていないかチェックしてみましょう。
今回の設定では、約1時間半(90分)でトレーニングが完了しました。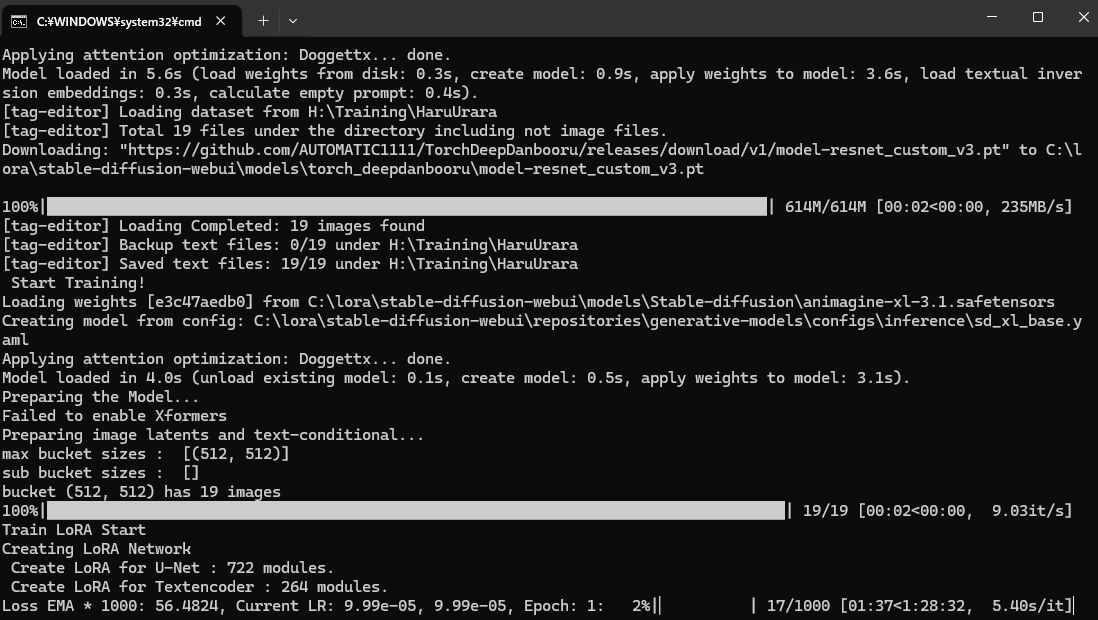
以上、簡単ではありますが最低限のトレーニングに必要な操作でした。
今のモデルとLoRAの再現力は、本気でヤバい

以前ご紹介した「Textual Inversion」も使い方でかなりいい感じになるのですが、なんせ時間がかかるのがネックです。
それに比べると「Dreambooth」は、かかる時間が圧倒的に少ないですし、今回のTrainTrainも同じくらいなので使い勝手が大幅に向上しています。
さて、ではそんな感じで軽く流してトレーニングしたモデルはどんな感じになったでしょうか?
早速できたばかりのLoRAで出力して見ます。
ちなみに、TrainTrainは、トレーニング終了後、勝手にLoRAを使えるように格納してくれます。
もう、なんて良い子!!
では、まずは実際に出来上がったLoRAで出力する方法を簡単に紹介しますね。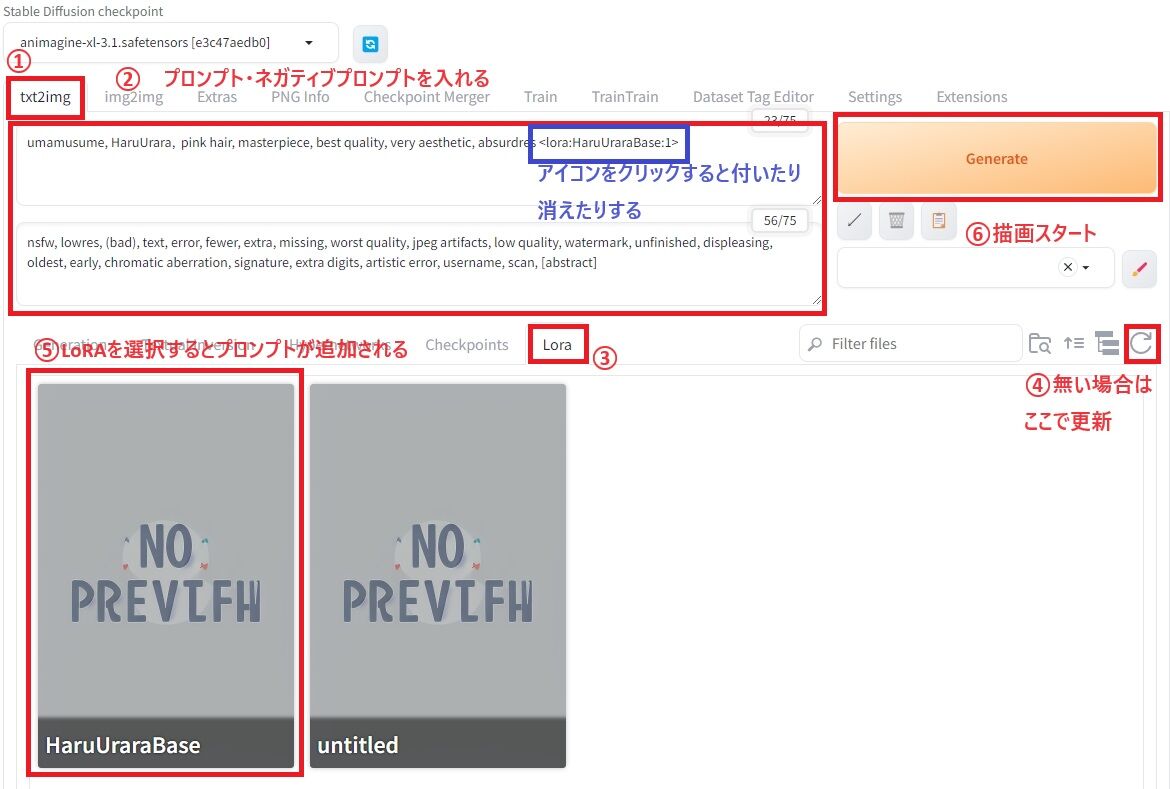
① txt2imgタブを選択
② プロンプト・ネガティブプロンプトを入力
ちなみに、デフォルトで使用したプロンプトは以下の通りです。
〇 Prompt
umamusume, HaruUrara, pink hair, masterpiece, best quality, very aesthetic, absurdres <lora:HaruUraraBase:1>
〇 Negativ Prompt
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
③ LoRAタブを選択
④ もし作ったばかりのLoRAが見つからない場合は更新ボタンを押す
⑤ 使いたいLoRAをクリックするとプロンプトに自動で追加される
なお、強度を強めたり弱めたい場合は数字をいじる(弱:1⇒0.5 強:1⇒1.5 など)
⑥ Generateボタンで作成開始
これだけなので、もう楽で仕方ないですね。
これにプロンプトの合わせ方を工夫すると、更に色々とできます。
では、まずはデフォルトでほぼなにもいじらない状態での出力がこちら。
全体的な雰囲気は悪く無いんですが、何だろう……目か?目が変だ。
これは、過学習気味なのと画像の解像度不足な感じがします、はい。
枚数が多かったから、これは「train iterations」が500でも良さそう?
やはりこの道は修羅の道ですね。
と言う訳で、再度、元のデータを見直しまして、以下のようにしました。
少し目の解像度が気になったので、一枚、目を大きく映している画像を加え、全体的に全身絵を抑えめにしました。
よくよく考えると、とりあえず顔を覚えさせないと話にならんと考えたからです。
服はそれぞれのLoRAを別に作って組み合わせれば良いのですから。
これを「train iterations」が500で回しました。
今回も1時間半くらいかかってます。その結果がこちら。
うん、悪くないのでは! ただし、まだちょっと目力が強い気がします。
これは今後の課題ですね。
では、少しウララ要素を落としましょう。
その場合は、LoRAの数値を落とします。
以下、それぞれの場合の比較です。
<lora:HaruUraraTest03:0.5>
<lora:HaruUraraTest03:0.75>
<lora:HaruUraraTest03:0.8>
<lora:HaruUraraTest03:0.9>
うーむ、どの子も可愛くて捨てがたいですが、0.8~0.9ぐらいが良さそうですね。
では、このバランスで、ウララ……ちょっと、結婚式してみようか(にちゃぁ
うむ、今日もハルウララが可愛い!!
前にDream Boothで作った時は、ここに鉢巻きとグローブがついてくる事態になりまして(アホ)
今の技術だと、私レベルの使い手でも簡単に思った形に落とし込めるので、利便性は格段に上がりましたね。
ただし、そうは言っても、今なお、何もしなければやはり細かいところはかなり荒く……
や、やられる!? やられはせん、やられはせんぞぉおおお!?
と叫びたくなるようなホラーな絵も散見しますし
ウララさんや? ずいぶん、ごつい手をなさっておられるね。
そこに指輪は、ちょっと遠慮したいんだが? え、待って、力強っ!?
あー、もう! 惜しい! 手が、惜しい!!
良いウララ成分があって大好きな感じですが、指、指ガガガ……。
みたいな感じで、こう、細部が非常に残念な感じなのはご愛敬です。
なので先にもお話しました通り、絵の描けない私には、まだ使いこなすには難しいツールであることは間違いありません。
とは言え、そこまで細部にこだわらないのであれば、完成度は上がってきたなと実感できるところまでは来たと思います。
しかし、実は、LoRAの真骨頂はこれからなのです。
このLoRAは重ねることが可能です。
実は、指の問題は以前からずっと指摘され続けていて、それは今なお、完全には払しょくできてないのですが、少しずつ対策が取られてきました。
そんな中で、割と即効性が高く、効果も高いLoRAが登場したのです。
そんな感じで、ちょっと試してみたのがこちら。
うーん、惜しい!!
けど、全体的なバランスが良くなった気がしますね!
お守り位な感じで入れておいて良さそうな気がします。
まだ課題克服とまでは行かない様子ですが、面白い使い方が出来そう。
ちなみに、私の環境では「hipoly_3dcg_v7-epoch-000012.safetensors」をloraフォルダにいれても、Web UI上では見ることができませんでした。
ただ、プロンプト自体は効いているっぽいので、そういう使い方で良いのかな?
もし間違ってたらごめんなさい。
皆さんも是非、内に秘めた魂を爆発させる道具の一つとして、活用して見て下さい。
総評 そろそろ実用レベルになってきた!
前の記事でも書きましたが私は割と時間がある方なのと、試行錯誤は好きな研究者肌なので良いのですが、これを一般の、しかも初心者の皆様がやるのは、まだ敷居が高いですね。
しかし、先にも書きましたが、一般の方でも使える統合環境が出てきたら一気に普及するなと思いました。
これも前の記事からの引用です。
① トレーニングさせる環境を用意するのが大変
私のようなPC主体に活動されている方は、既にハイスペックの物をお持ちの方もいらっしゃるでしょうが、大抵の方はそんなハイスペックなPCは無いと思うんですよね。
特に絵描きの方は、グラボのないPCで満足しちゃうようですし、ゲーマーでもない限り、そもそもこのスペック群のPCは持ってませんよね。
なので、よほどのお金持ちや興味のある方以外は、スタートラインにすら立てないのが現状です。
ちなみに、参考までにですが、ここ辺りのレベルなら恐らくは使い物になるかと。
メモリとストレージがやや不安があるので、そこを強化すれば3年は戦えるPCかと思います。
問題なくAIちゃんもトレーニングできるはずです。
ただ、技術が進んで使用メモリ量を削減できるようになれば、もう少しグラボの選択肢は広がると思います。
それが数週間先の事なのか、数年先の事なのかはわかりません。
なのでご自分の財政状況とその他諸々踏まえた上でご検討下さいね。
② 仕組みや使い方を理解するのが大変
基本事項を理解するだけでもかなり大変な上に、最近の更新頻度がとんでもなく高いせいで、そのハードルが更に爆上がり状態です。
この記事がここまで遅れてしまったのは、そもそも一般人レベルが使えないレベルだと判断したからです。
この記事を読んで下さった皆様の中にも、まだきついと感じる方も多いでしょう。
そんな感じで、基本的にはまだ万人が楽しめるレベルでは無いのですが、私のように楽しみたい方には、おススメできます。
ただし、原則、自分で調べる能力が無いと話にならないので、茨の道であることはお覚悟ください。
その上で自分の絵を作り出してみたいなと思っている紳士淑女の皆様の力に少しでもなれたらなら幸いです。
また、本当に重ねて何度も申し上げますが、人の絵は勝手に使っちゃダメですからね?
今回の記事は以上になります。
お読みいただき、ありがとうございました。


コメント
大本となるモデルについて権利の透明性が担保されてない、
そこまで理解していらっしゃるのなら使用を続けることに疑問を抱いてほしかったです。
あなたも再三「他人の絵を使うな」と念を押しているあたり、「自分の作品が望まぬ形で利用されること」がどれほどの苦痛か分かってくれていることだと思います。
ですがそもそも生成AIは「数十億の画像を無断利用したデータ」を使用しています。LoRAというのは「追加学習」で結果を調整しているにすぎません。
生成AIを使用した時点で「他人の絵を勝手に使っている」のです。
そしてその「他者の著作物を無断で使用している構造」に様々な業界で批判の声が上がっています。
AIを同人活動に例えてましたが、生成AIは黙認ではなく、「やめてと言っているのに無視されている」のです。
生成AIの登場で、絵描き側には
「絵を投稿した瞬間に贋作量産、またはそのツールの機能向上に使われ間接的に他の絵師の被害」
「流行りの絵柄が狙われ、オリジナルの絵師が『AIっぽい』等と言われる」
「AIを隠して投稿する者や言いがかりをつける事例が増加、見る側も疑心暗鬼にかられる→絵を発表する環境自体の棄損」
挙句
「AI学習禁止ですと言っても『お気持ち』と揶揄され勝手に奪われる」
「生成AIで絵師になりすまし、迷惑行為を働き絵師に悪評を押し付ける」
などといった事態が実際に起きています。
以前と比べて絵は投稿しづらくなりましたし、心を病む絵師もいます。AI学習が嫌で過去絵を消した人もいます。私とか。
つまり創作界隈全体を委縮させているんです。
絵師にこそ使ってほしい?それは仲間をいじめる側に回れと言うのと同じことです。
もちろん個人で楽しむのは自由だ、と言われれば反論できません。ですがお願いです。
これ以上「面白い玩具」レベルの認識で広めるのはやめてください。
長文失礼しました。
>>1
くろっしゅさんへ
こんにちは
この難題に心からのコメントありがとうございました
まず、何度も記事内で書いている通り、自分の作品が望まぬ形で利用されている状況については、私も危惧しております。
だからこそ、この記事を書きました。
それは存分に書いたつもりでしたが、結果として心労を与えることになった点に関しては、申し訳ありませんでした。
くろっしゅさんの仰る事は、絵師様の立場として実に切実な訴えですし、辛い気持ちが伝わってきますね。
挙げて頂いた数々の例についても私は理解しておりますし、その心情を考えているからこそ、この記事を出す時期や内容も何度も変更して、この様な形に落ち着きました。
今回のコメントを拝見して、本当にAIに対して憎しみが強いのだなと言う事は良く分かりました。
そして、くろっしゅさんのコメントを見て、色々と考えを深めてくれる方もいらっしゃると思います。
なので、私はその言葉をただ受け止めるだけとしたいと思います。
考えやその立場は異なりますが、くろっしゅさんにとっても良い時代が来てくれればと願ってやみません。
ではでは。
>>2
泉絽さんへ
お返事ありがとうございます。
そして当たり強めの意見を温かく受け止めてくださりありがとうございます。
確かに、私は憎しみのあまりちょっと思考が短絡的になっていたかもしれません。『泉絽さんは過去に生成AIの記事を書いていた以上、時代が動きつつある今、改めて現状と注意喚起を読者に説明する役目があった』という部分に考えが至りませんでした。
その点を謝罪させてください。申し訳ありませんでした。
そして私としても、使う人はどう考えているのかという点で知見が得られました。ありがとうございます。……まぁその上で私のスタンスは変わりませんが(
未来の利便性を語るのは今の大きすぎる被害をどうにかしてからと思っていますし、悪用する人が悪いだけで道具は悪くないとするには被害が大きく悪用に便利すぎるし、そもそも根底の作りがあまりに膨大な無断利用=権利侵害だと思っているのでいくら気を付けようと問題意識持ってようと使うべきでないという考えで、身近に使用している人がいたら止めます。
そこは譲らないのでよろしくお願いします。(笑)
あと繰り返しになりますが黙認されているという認識は危険なので改めたほうがいいと思います。特にネット上では、日本はともかく海外のほうで生成AI規制の波来てますしもっと風当り強いので……。
連投失礼いたしました。
>>3
くろっしゅさんへ
こちらこそ、心境的にはとても難しい状況の中、返信いただき本当にありがとうございます。
また、私の記事の趣旨を的確に理解していただき、重ねて感謝ですよ。
くろっしゅさんを始め、絵師様の気持ちを考えれば記事は出すべきでは無いのですが、現状がそれを許してくれません。
私の記事が、現在の悪い流れを少しでも軌道修正するきっかけになればと書いています。
ただ結果としてくろっしゅさんの様な絵師さんに不快な思いをさせてしまったことは、本当に申し訳ないです。
私は基本的にAIの可能性を模索する側の立場ですが、権利の扱いに関してはくろっしゅさんの懸念する事項におきまして、同意であります。
ただし、だからと言って使うこと自体を止めさせることは、まず論拠が乏しい(どの画像がどのモデルに使われているかを証明する必要がある)上に、今度はそれ自体が違った意味での強制になりますので、私はそこに慎重な立場なのです。
ただ重ねて申し上げますが、その憤りやお気持ち故の行動であり、信念であることは承知しておりますので、そこは否定する気はありませんよ。
寄って立つ立場が違いますが、私はくろっしゅさんの意見も理解していますし、可能な限りにおいて尊重したいと思っています。
また御忠告も感謝いたします。
確かに、海外の方でも動きがありますが、まずは日本の法整備の状況次第ですね。
願わくば国家的にクリーンなモデルの生成を舵取りしてくれると良いのですが、それには絵師さんの意見と協力が必要です。
その方向で、絵師さんの権利が保たれるように、上手く動いてくれればと願ってやみません。
丁寧で紳士的なコメント、ありがとうございました。
ではでは。
おっすくれすさんだよ。
前記事から圧倒的に進歩しててすげぇなステーブルデフュージョン。
準備段階で要求されるパソコンスペック、実行するまでの手順が複雑怪奇っぷり、それを乗り越えてなおリセマラ(言葉が正しいかは知らん)、ある種の苦労に見合う進歩をしているような気もするね。
泉絽君も相当時間かけて出力した画像をそこからさらに厳選して掲載してそうだし、しっかり使えばクオリティ高い絵が出力されるんだなあ。と感心する反面、耳カバーと飾りが安定してないのがすげぇ気になるなあ。そのキャラクターにとって重要な装飾品を確実に描写するみたいな、そゆ細部の甘さがまだまだ弱点と言うか。たぶん指示を細かくしちゃうと耳だけに力が入って他がおかしくなりそうだし、適度なところで出力してそれを修正する人の手がまだまだ必要なんやな、と思いました。まる。
うんまあ、目が肥えたら自分で描いてみようぜって言うお話。
手のゴツさとかここがウララっぽくないとか、ちゃんと見る目もキャラ愛もあるんだし、そのスペックのパソコンがあるならペントソフトも余裕で動くじゃろ。イイ感じで出力できたやつをベースにカスタムして君だけの最強ハルウララを作り出そう!いやまあ、最初にコメントしてる人の言ってる通り、著作権周りが良くわからんからそれもアウトなんかな。ワガランナァ。
>>5
くれすさんへ
こんにちは。
相変わらず凄く微妙な立ち位置の記事に、凄く前向きなコメントありがとうございます!
個人的には初期に比べるとかなり敷居は下がったかなぁと感じているのですが、まだまだ一般水準には落ちてない印象は強いですね。
くれすさんのおっしゃる通り、まだリセマラ的な試行錯誤が必要な部分もあるのですが、実は前に比べると望む構図に最初から近づける事は可能になってます。
ただ、これもご指摘の通りで、それなりの知見と経験則が無いと制御しきれないのは変わらずという感じですね。
あ、実は今回ご紹介したものは、そんなに時間かかってません。
やり方を調べたりLoRAの試行錯誤の方が比重が高く、出力自体は総数でも100枚ほどだと思います。
昔は1万近く出力してたので、その時期に比べると100分の1の労力でここまで来れるようになったと言えなくもないです。
耳カバーとか鉢巻の描写とか安定してないのは、やはり絵の選別が悪いのが原因ですね。
ただウララの鉢巻無し絵を用意するのが難しかったのです……その最初が用意できないので、これが絵師さんとの明確な差ですね
だから絵師さんがしっかり理解して修正も含めて使いこなしたら凄い事になりそうだなぁと言う印象は当初の通りです。
自分で描いてみるとの提案もありがとうございます!
実は、クリスタはあるので、画像編集のスキルアップという意味では使いこなしてみたいところではあります。
問題は、凄く細かい所を修正するなら頑張れば行けそうですけど、そもそも描きたいという絵が思い浮かばないので、今はまだ厳しいかもですね。
ただ、前向きな提案ありがとです!
著作権周り難しいですよね。
私も積極的に加害者側に回りたいわけではないので、そういう所も気をつけつつ、色々考えてみたいと思います。
ではでは。