
皆さま、こんばんは。
このような辺境まで、お越し頂き、ありがとうございます。
Twitterやネットでの情報を追っている皆様は既にご存じかと思いますが、日々、画像描画AIの進歩が止まりません。
一応、今は画像描画AIの祖ともいえる「Stable Diffusion」だけでなく、沢山のモデルが世に出ておりますが、私は敬意を表して今後も描画AIの事を表す言葉として、Stable Diffusionとして語りたいと思います。
で、そちらを何とかローカル環境で使おうと奮闘したのが、前回までの記事の内容になります。
いやぁ、なかなかに厳しい戦いです。
そして私のやっていることはあくまで基礎レベルなのですが、毎日のように一定数の迷い子達が訪れてくれておりまして、私が思ってもみなかったレベルで読まれているようです。
やはり需要自体は非常に高いんだなぁという事を改めて感じます。
そこで、今回は更に次のステップのお話をするために、記事を書きました。
しかし正直に申し上げて、この記事を書くかは最後まで迷ったんですよ。
それは表題にもあります通り、遂にトレーニングについて語ることになるからです。
しかし、あまりこの手の話に詳しくない方は、「???」となると思います。
そんなことで、今話題のStable Diffusionについて、相変わらずのポンコツな私が使用できるようになるまで苦労したことや、思うところについて書き残しておきたいと思います。
【注意】
今回は、トレーニングについての記事になります。
その為、著作権や絵師様への配慮等、様々な問題に絡みますので、くれぐれもこの技術の使用には細心の注意をもって対峙して下さい。
また、この記事は主に、プログラム関係に馴染みのない方に向けて作成しております。
私はあまり知識が深くないので、今回も凄ーくどうでもいい事で苦労していますので、既にその手の方面に知識のある方には理解できない部分で躓いているためイラっと来る人もいらっしゃると思います。
知識の深い方には、素人が右往左往する姿を楽しむ位しかできない記事かと思いますので、そのつもりでお進みください。
トレーニングって何?

nnさて、今までの記事でもご紹介致しましたお絵描きAIであるStable Diffusionちゃんですが、こちらは簡単に言うと与えたキーワードを基に絵を描いてくれるというものです。
そしてそれらをより簡単に使えるようにUI化したツールがStable Diffusion web UIとなります。
セットアップや使用する環境は、現段階だとかなり難しい側面があるので、まだまだ一般的ではありませんが、やれることは日々進化しつつ増えており、皆さんの手元で楽しめる日も遠くないでしょう。
とは言え、その場合は恐らく課金等、お金を払って環境を借りることで楽しむ形になると思います。
しかし、中にはそれでは嫌だという方もいらっしゃると思います。
例えば、特定のマイナーなキャラクターやシチュエーションを書きたい。
自分の絵の延長で、もっと沢山の絵を作成したい。
そういった方の場合、大衆向けのAIモデル(AIの頭脳の様なもの)では、対応できません。
そこでどうすればいいか?と言う話になるのですが、
トレーニングすることで絵や概念を覚えさせるという選択肢があります。
つまり、今のAIちゃんがその絵を描けないのは、知らないからです。
例えば、私は縞パンやブルマが大好物なのですが(いらないカミングアウト)、ノーマルのStable Diffusionモデルでは、それを指定して書かせることができません。
同じように特定のキャラクターなども、その概念がインプットされていないので、描けません。
なので、それを知らない無垢なAIに、未知の概念をじっくりたっぷり教え込む必要があるのです。
それが「トレーニング」や「ファインチューニング」と言った機能になります。
トレーニングに際して、忘れてはいけない事
いつもですと、すぐに実践編へと移行するのですが、ここで大切なことを先にお伝えしておきます。
なお、この記事を書く上で私が伝えておきたい事である、超基本的な話なので、もう既に知っているよ!っという方は、この章は飛ばしてくださいね。
このトレーニングを行うには、当たり前ですがAIちゃんにその概念を教える教材が必要です。
そして例えばですが、私が大好きな花騎士のシクラメンちゃんを描きたいと思っていたとしましょう。
では、その絵を片っ端から集めて学習させるのは、良いのでしょうか?
私は、現時点で絵師の許可なしにAIをトレーニングすることはお勧めしません。(って言うかやめた方が良い)
いちオタクとしましては、絵師さんの心境や尊厳を思うと、それで筆を折ってしまう事も十分に考えられるからと言う理由が一番大きいです。
ですが、私の意見に関わらずそう思わない人はやるでしょうし、その流れが止まらないとも思っています。
何より、じゃあ、何で私はこの記事を出したんだ? と言う話になる訳ですが、それはむしろ絵師さんにこそ、このAIの可能性とできる事、できない事を知って欲しいからなんですよね。
私が書く書かないにかかわらず、もう既に技術は私の手の届くところに来ております。
半年たってないですよ。それでこの状況ですから、遅かれ早かれ、皆さんの手の届く場所には登場することになるでしょう。
その時、心を折らずに向き合って欲しいからこそ、このような記事を書いてます。
同時にこれは、私のような絵の描けない創作者の創作活動の幅を広げるツールにもなります。
今まで手の出せなかった分野が開拓されることで、更に多種多様なコンテンツが生まれる事でしょう。
私はその可能性の方を重視しているという立場でもあるので、今回の記事を書くに至りました。
AIで絵を描く事はずるいのか?
ついでなので、私の考えをもう少しここに書いた上で、先に進みたいと思います。
先日、ネットサーフィンをしていると、とある絵師さんがこんな事を呟いておりました。
AIで絵を描く事は、ゲームでチートを使う事に似ている(めっちゃ概略)
私はこのつぶやきを見て、なるほど!そういう感覚なんだな!と凄く腑に落ちました。
ちなみに、この方は本当にとても魅力的で可愛い絵を描いて下さるのですが、それまでの苦労する様子も見ているので、余計に色々と思う所がありました。
なので本来、この場所に例として出すのもどうかと思ったのですが、これ以上に絵師様たちの心を雄弁に物語る表現が見当たらなかったので、感謝と敬意をもって引用させていただきました。
で、まずはこの言葉に関しての、私個人の見解としましては、全く持ってその通りだなと言う感想です。
例えば、今は、はやってるのか?よくわからないFPSの対戦型のゲームとかでも、知識、戦略、操作などなど、沢山のプレイによって独自に積み上げて来たものがあると思うんですよ。
私もよくやるモンハンとかもそうですし、大抵のゲームってそうですよね。
それがいきなり横から何をやっても勝てないチートキャラが出てきて無双し始めたら、「はー!? くそゲー!?」ってなりますもんね。
そりゃそうですよ、私もそう思います。
ただ、ここからはちょっとドライな話になって来るんですけど、それは体験を主な楽しみとして味わうゲームだからこそ、そう感じるという側面もあります。
ゲームが楽しいのは、勝つことや目的を達成することによる達成感もあるでしょうが、その過程において得られる体験が実は最も重要なポイントになると私は思っています。
例えば、先のFPSなどは、勝つことが主目的です。
で、チートをする側からすれば、気持ちよく勝つから使うという意味でしかないんですよね。
チートする人にとってみれば、勝つことが至上命題でありそれ以外はどうでも良いのです。
対してゲーム自体を楽しめる人は勝ち負けはその一つにしか過ぎないんです。
仲間と共に戦い試行錯誤する体験そのものに価値を見出すこともあるんですよね。
たとえ負けてしまったとしても、そこに何か価値を見いだせれば良しとする人です。
しかし、それをズルで壊されるわけです。全てを否定されたと感じるのは当然です。
勿論大前提としてゲームの場合は、そこに世界を構成するルールが存在するのでチートを使ってそれを逸脱して捻じ曲げる方法は論外です。ダメに決まってます。
ただ、考え方と言う意味において、チートをする方の考えと、ゲームを楽しむ方の考えの違いを比較するとそういう事なんですよね、きっと。
じゃあ、絵はどうなんだっていう話なんですけど、これ、私は残念ながらひっくり返ってチートをする側の気持ちなんです。
つまり、表現したい絵がこの世に出てくるなら何でもいい、なんですよ。
翻って絵師さんからすると、このAIはまさしくチートそのものです。
はー!?くそゲー!?ってなります。
ですから、心情的にはよくわかるし、当然のことだと思います。
ただ一つ、私から見れば先ほどの例と明確に違っているところがあるんです。
私から見れば着地点がゲームと違ってまして、この「絵を描く」という事に関しては、世界が課した厳密なルールも無いですし(著作権はありますが)、目的地は「絵をこの世に出す」という一点しかないんですよね。
ちなみに神絵師になるとか有名になるって言うのも絵を描く目的に見えると思うのですが、絵と言うもの自体を生み出す動機とは違いますよね。
絵を描くこと自体が目的ではなく単なる手段であり、話が変わってきてしまいますのでそこは別問題だと思いますし、今回は外します。
なのでゲームの場合は勝ち負けが存在するのですが、絵においては自分の納得できる絵を描き切るということがゴールになるのかなと思っております。
勿論、絵の上手い下手、好み等様々な要素はあると思うのでちょっと乱暴な意見であることは重々承知しております。
ただ、ある一定水準以上は技術的にはあまり意味の無い話なのかなぁと私は考えてますので、その辺りをクリアーするという前提で考えればあながち間違ってもいないかなと。
なので絵を描く事、それ自体が得難い経験であるという事は大いにあるでしょうが、先ほども述べた通り、どうであれゴール地点はある程度自分の納得できる絵が完成することなのかなと私は思っています。
ただ一つ補足すると、絵を描くという行為自体が楽しいからやっている方もいらっしゃるでしょうし、それに誇りを持っておられる方もいらっしゃるでしょう。
それはとても意義深いことで、その技術や心意気に関して向かう姿勢に対して、私は賞賛の言葉しか出てこない訳です。
なのでその体験そのものを否定するつもりは毛頭なく、むしろ推奨しているという事は、間違えて欲しくないので強調しておきますね。
で、話はとっちらかりましたが、ようはどうにせよ、チートだろうが何だろうが、自分の目指す絵が描けるならそれは、どちらに転んでもOKなのではなかろうか? と言うのが私の主張なわけです。
絵を描く楽しさも意義も、AIちゃんが否定している訳では無いです。
あくまでAIちゃんは、絵を上手く書くツールの一つでしかないので。
ですから絵師さんとしても、感情としては凄く理解できるわけですが、いずれはAIが出てきて楽できるわーって思っていただけるような世の中になれば良いなぁって思っています。
今の形だとまだ絵師さんの需要を満たすサービスはそれほどないと思いますが、先日、SNS上でフルボッコにされてしまったmimicさんも、サービスを開始したようですし、こういった動きがドンドン広がっていけば良いですね。
私が今回、この記事を書くに至ったのも、このような絵師さんがもっと楽になる手段の一つとして、ご紹介したい側面があったからです。
そしてこれは記事を読めばわかりますが、AIにはできることが限られているため、絵師さんの全てを否定する存在にはなりません。
改めてそういう意味で、絵師さんにこそ、この記事は読んで頂きたくて書きました。
また、AIを使って絵を描いてみたい方も、そういった絵師さんの心情を鑑みて絵を勝手に使ったり盗用するのはやめましょうね。
Stable Diffusion web UIでトレーニングしてみよう!
前置きが長くなりましたが、大事な事だったので。
では、例の如く私のPC環境をある程度こちらに記載しておきたいと思います。
・CPU
Core i7-12700

・OS
Windows 11(NEW)
・私の知識レベル
Java ScriptやGASなら書けるくらい
Python?最近流行ってるよねーくらい
開発環境? 何それ美味しいの?(テキストベタ打ち)
ちなみに、ネックとなるのはグラボでした。
そう、ここに通ってくださっていた皆様は、お気づきですね?
遂にグラボを新調いたしました!
半年前の悲劇からようやく復活!と思いきや手が滑った(アホ
だってー、トレーニングしたかったんだもん!
快適にAIでお遊びしたかったんだもん!もん!!

悪くないグラボだったしまだまだ現役で使えるんですけど、いかんせん、AIで遊ぶにはちょっと役不足でした。
それでも、チューニングすれば出力だけならいけてたので、今回の記事とは別にただ出力したいだけなら、選択肢としてはありだと思いますよ。
だけどその値段出せるなら、もうワンランク上行っとこうか?ってなりますよねー。
今までなぜトレーニングしなかったか? それはメモリが足りないから
GeForce1660Superちゃんも、凄く良い子なんですよ。
大抵のゲームはサクサク動くし、普通に使う分には問題なしです。
ですが、このAIでお遊びするにはやや役不足でした。
特にメモリが……肝心のメモリが6Gと、すれすれを狙ってる辺り、本当にもう!(何
ちなみにトレーニングをするには最低8G必要だと言われております。
色々と試してあがいては見たのですが、今の技術力ではこの壁を突破するのはかなり難しいという結論に達しまして。
メモリーエラーの壁はどうやっても突破できませんでした。しくしく。
で、そんな折に遂に新しいグラボたちが出てきておりまして、その中で私が前から密かに狙っていたGefoce3060が安くなってきたので、思い切って手を出しました(10回ローン)
何で今なのかと言いますと、実はこの記事を書いている時点で3千番台の上の4千番台が出始めてるんですよ。
この4千番台のトップを切ったのが4090なんですけど、これが巷では化け物過ぎて物議を醸しだしておりまして。
その後続で、4080が最近発表されて、これから半年くらいかけて市井用のものまで落ちてくると思うんですよね。
で、それを待つのも一つの手だったんですけど……
何故かここに来て3千番台のデチューン版が来てまして。
先ほど、私が購入した3060はメモリ12Gなのですけど、デチューン版は8Gなんですよね。
それでも問題は無いと思うんですけど、これでトレーニングできなかったら割と凹むなぁと思いまして。
あとこれが出てきたという事は生産はもうしてないでしょうし、これからなくなる一方です。
この流れだと、4060は8Gの可能性が高く、しかも4千番台の傾向として割高になる可能性が極めて高いため、待つのは微妙と判断しました。
また、チラッと調べた感じ3060のトレーニング記事ってあまりなくて、なら人柱もかねてやるべーとなりまして、この記事を書くに至っとります。
古い3060はお値段もミドルクラスのグラボにしては手ごろですし、この先もしかしたらもっと下がるかもしれませんが、その前に無くなる可能性もあります。
なので、もし興味がある方で、狙っていた方は本記事を参考にしてみて下さい。
結論から申し上げますと、3060(12G)でなら何の問題もなくトレーニングできてます。
あれれ? Stable Diffusion web UIが起動しないぞ?
さて、この記事を書くにあたって久々にStable Diffusion web UIを起動したのですが……
なんかエラーを吐いてるじゃないですか。
色々調べてみたら、なんでかPythonのバージョンがおかしなことになってたので、全部一旦アンインストールして入れなおしました。
多分、Windows11に移行したので、その過程で何かが起こった模様。
もし仮に同じようにいきなり起動しなくなった場合は、移行の影響も視野に入れて見て下さいね。
ちなみに詳しい環境構築方法は、前にもご紹介しました以下のサイトがとても参考になりました。
と言う訳で、詳しいセッティング方法はこちらのサイトに感謝しながら行いましょう。
とりあえず、注意点としては以下の部分ですかね。
① Pythonは3.10.8を使いましょう
実は新しいバージョンで3.11.0が来てるのですけど、そちらだと上手く動きませんでした。
多分、ソースでバージョンを縛る部分があるっぽいです。
なので、3.10.8を選んでインストールしましょうね。
〇 Download Windows installer (64-bit)
インストールの際には、下部の「Add Python 3.10 to PATH」にチェックを入れる事をお忘れなく。
最悪間違ったらアンインストールからの再インストールでもOKです。
② Git CUDA は最新のものでOK

CUDAも最新版で良かったですが、参考のサイトでも書いてますが、ややダウンロードページが見つけにくいです。

とりあえず、現状での最新版にリンクを張っておきます。
もしかしたら今後、バージョンが上がったらダメになるかもなので、その場合は11.8を探してみて下さい。
では、誰をトレーニングしようか?
と言う訳で、長々と語りましたがやっと本番です。
長くなりすぎてお忘れの方も多いと思いますので、今一度釘を刺しておきますが、
許可の取れていない絵師さんの絵でトレーニングするのはやめましょう。
と、ここまで口を酸っぱくして言ったのと、ここに来るオタクの皆様は基本的に紳士淑女(意味深)なので、信じております。
じゃあ、そういう私は何をトレーニングするんだ? と言う話です。
あ、まず、最初に宣言しておきますが、
私は、今までお世話になった絵師様の絵を勝手に使ってトレーニングしないと誓います
じゃないと折角、今まで私の依頼を受けて下さった沢山の絵師様に申し訳ないですからね。
仮にするにしても許可は必ず取ってから動きますので私と関係のある絵師様(含む花騎士)はご安心ください。
逆に、自分の絵を使ってトレーニングさせて欲しいという知り合いの絵師様がいて、この記事を見て興味を持たれましたらお気軽にDMにでもどうぞです。
話は戻って「じゃあ、どうするんだ?」と言う事になります。
今、サクッと手元に手に入るフリーの版権の絵って「いらすとや」と「東北ずんこ」さん位しか思いつきません。
東北ずん子さんの方は、めたんちゃん絡みでいずれはお世話になりたいのですが、実は今はちょっと先にどうしても試してみたい子がいるんですよ。
そうです、ハルウララです。
え? 大丈夫なの? と思われる方もいらっしゃると思うのですが……
正直、わからないです(ぉ
ただ個人で管理する範囲ならOKなのではなかろうかと、私は判断しました。
あと皮肉なことに明確な絵師さんと言う個人の存在が表にいないので(もちろん会社内で絵師さんはいらっしゃるでしょうが)、手を出しやすかったという側面もあります。
これが個人の絵師さんなら、めっちゃ嫌だと思われるので私もやりませんけど、会社と言う母体なら、いいんじゃないかな?かな??位の感じになるので(ダメだったらやめます)
ちなみに花騎士は、後ろに絵師さんがめっちゃ控えている文化ですし、他のソシャゲーもそういうのが多いので、私は手を出しません。
で、ウマ娘の場合、規約的には、エロい事をさせなければ問題ないはずです。
やっていることは、同人活動の延長であるはずなので。た、多分。
ただ誰かがどこかでエロい事させてそうな気がしますので、余波で一緒に流される可能性は否定できません。
その場合は、こちらのブログ記事が吹っ飛びますので、指さして笑ってやってください。
なので、もしこの記事を読んで同じようにやりたいなーと思っているそこの紳士淑女の皆様!
ある程度結果が落ち着くまでは真似するにしても表に出さない方がいいよ!と言っておきます。
で、何でそんな事やろうとしているのか?と言う話なのですが……
勿論、沢山のウララの絵を見たい!っていうのもあるんですけど、
手前味噌で恐縮ですが、今、こちらの動画の続きを作っていて、どうしても絵が足らんのです。
丁度、サムネイルになってる部分の絵とか妥協の産物なのでこことか、後、表現したい絵とかもう、全然足りないんですよね。
そもそも、ゲームが縦長なので、横長の動画に合わなさすぎ!(唐突な愚痴
私がどれだけシーンを合わせるのに気を使っているか!(雑魚MADですが)
構図とか理想の描写は頭にあるのですが、それを外に出す手段がないのです。
実は書いて欲しい絵師さんがいらっしゃるのですが、それはそれとして、やはり自分である程度何とかできる手段も持っておかないと無理かなーと思い至りました。
よし、ならこれでウララっぽい何かが仮に描けるようになったら、何とかなるんではなかろうか?
そういう魂胆で今回は動いてます。
いや、可愛いウララ見たいじゃん。本当は色々な子も見たいけど、ここが妥協ラインですわ。
また先ほども書きました通り、割と微妙なラインだとは思いますので、権利者より突っ込みが入った場合は即座に対応しますね。
その為、この記事自体がサクッと消える可能性があることもあらかじめご了承ください。
では、トレーニング開始!
さて、では具体的なお話に入ります。
AIちゃんにハルウララの良いところを沢山教え込んで、忘れられないように刻み付けるのです、ぐへへ(ダメ
ちなみに、過去、色々と試した時の名残で、基本的な工程は理解しているのですが、こちらのサイトがとても簡潔で分かりやすいんで紹介しておきますね。
上記のサイトの「Textual Inversion」の章が今回のメインとなります。
この「Textual Inversion」と言うのは、絵を学習してトレーニングさせるプログラムの始祖であり、その機能が「Stable Diffusion web UI」に「Train」タブとして組み込まれています。
なお、トレーニングするにあたって以下の設定を起動batである「webui-user.bat」内の「COMMANDLINE_ARGS」に設定しております。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --deepdanbooru
call webui.bat
では、上記のサイトを参考にしながら手順をおさらいしていきましょう。
① 学習元になる画像ファイルを用意する
今回はウララの可愛い姿を集めました。
ちょっと多いかもしれませんので、初回はもう少し少なくていいのと、基本は顔のアップが良いと思います。
これは後で書きますが、ある程度部位を絞って、その都度「Initialization text」と、後述するタグ用テキストの内容を変更したり、最適化した方が良さそうだと思いました。
② Embeddingを作成する(Create embedding)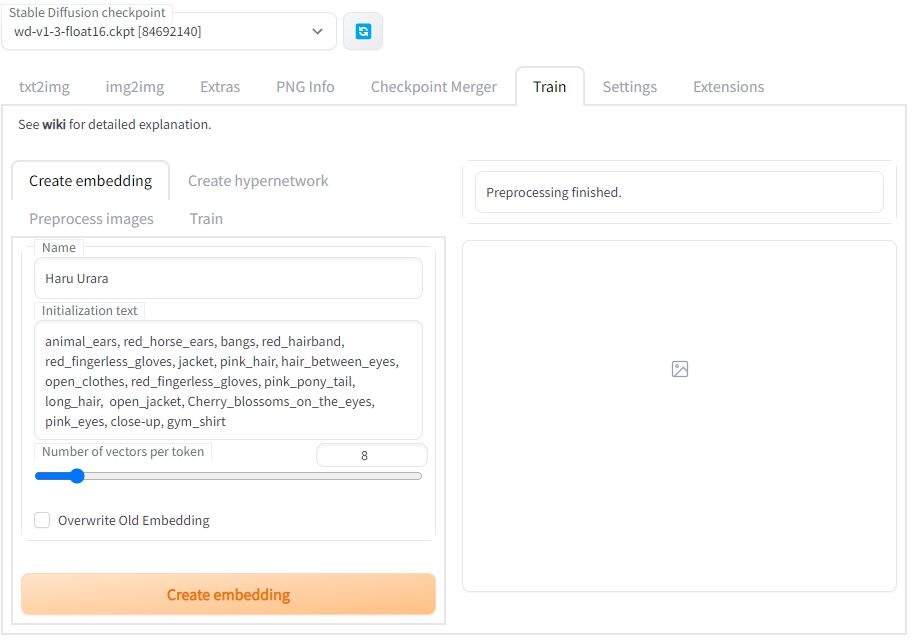
ここがまず最初のポイントです。
これ、私も良く分からないまま何度も繰り返して失敗を積み重ねた上で何となくわかってきたんですけど、大事な点を以下にまとめます。
〇 Name
これがプロンプトになります。
なので、覚えさせたい概念がある場合は、このネームがそのまま来ます。
最初、何でもいいのかなと思っていたので、そもそも呼び出しが安定しなくて、???ってなりました。
〇 Initialization text
上記、Nameに紐づけたい属性をこちらに記載します。
今回の場合は、ウララの特徴を表す語をここに入れます。
ここも多分あるあるポイントだと思うんですけど、あまり欲張って色々と入れると破綻します。
この場合はウララを表す絶対的な特徴を入れておきます。
ポイントは、確実に絵の中にある特徴ですね。
最初は訳が分からず、服装を含め全て入れました。
しかし、そうしてしまうと服が変わると破綻する上に、服装自体を変えることが困難になります。
なので今回の例だと、ウララは顔の部分と身体的特徴は絶対に変化しませんので、その特徴を主に描きだします。
small girl, animal_ears, red_horse_ears, bangs, pink_hair, hair_between_eyes, pink_pony_tail, long_hair, Cherry_blossoms_on_the_eyes, pink_eyes, white ribbon hair_between_eyes
試行錯誤した所、今のところ何となく良さげになってるのが、こういう感じでまとめたものです。
〇 Number of vectors per token
とりあえず8位がいいよみたいな感じなので、8にしておきます。
何でなのかはわかってませんが、動けばいいのよ動けば(いつもの)
上記の設定を行ったら、
「Overwrite Old Embedding」にチェックを入れると、今までのEmbeddingを継承したまま続きを行います。
別のものにしないなら、更新する際にチェックを入れて積み増すのもありかと。
私も今回は、こちらにチェックを入れて色々変えながらトレーニングしました。
③ 学習元になる画像ファイルの加工とタグファイルの作成(Preprocess images)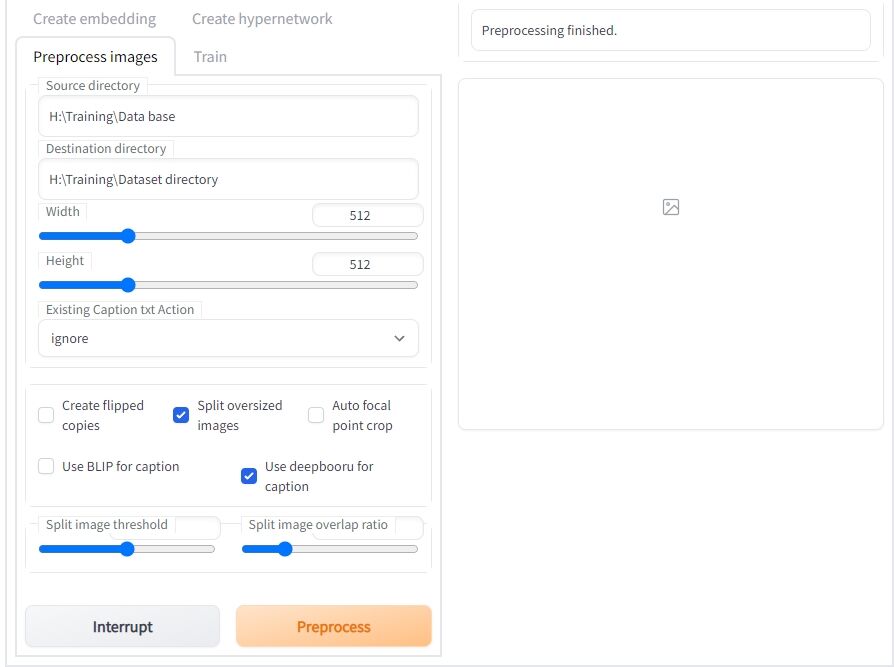
このタブは、トレーニング画像を参照し、よりトレーニングに適した形に加工する場所です。
「Source directory」に、トレーニング素材画像が入ったフォルダパスを入れます。
パス? どうするの?と言う方は、エクスプローラー(ファイルを見るウィンドウね)の、上の方にある場所が書いているところで右クリック>アドレスをテキストとしてコピーを選んでそのまま、貼り付けましょう。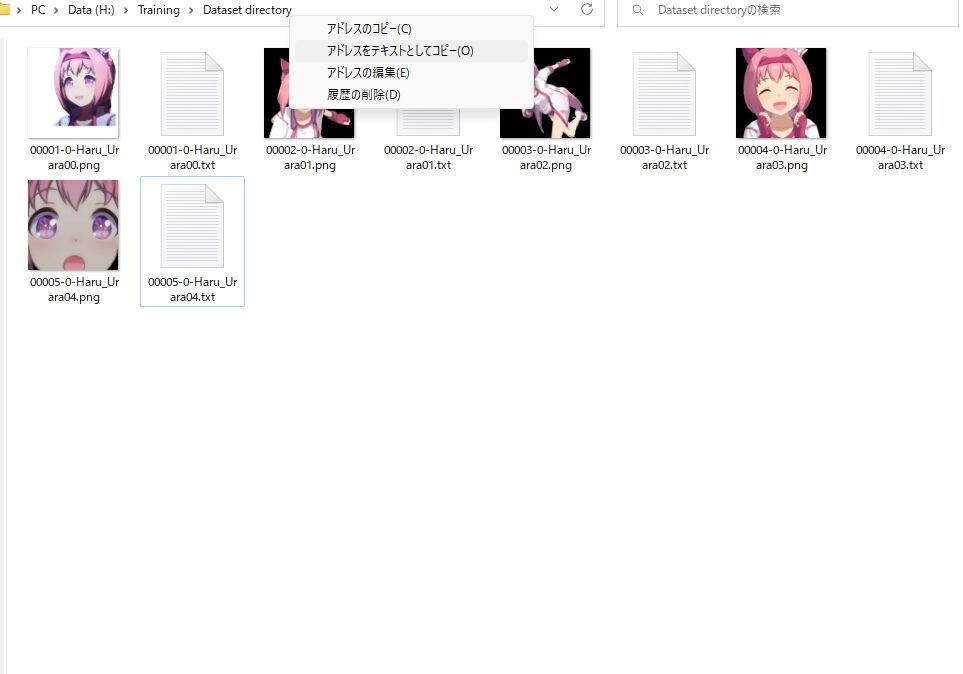
同様に、「Destination directory」へ今度は処理をした後のファイルを保存する場所を、貼り付けましょう。
後は、下のチェックボックスの欄で、「Split oversized images」と「Use deepbooru for caption」にチェックを入れます。
ここで、もし「Use deepbooru for caption」が無い場合は、起動の際に使った「webui-user.bat」に「–deepdanbooru」を入れ忘れているか、「webui.bat」で起動している可能性がありますので、確認して見て下さい。
それでもダメならインストール段階で何かおかしくなってる可能性が高いので、再インストールしてみましょう(フォルダごと消して入れなおすだけ)
最後に「Preprocess」ボタンを押せば、処理が始まり、以下のように、512×512に加工された画像とテキストファイルが対で出力されるはずです。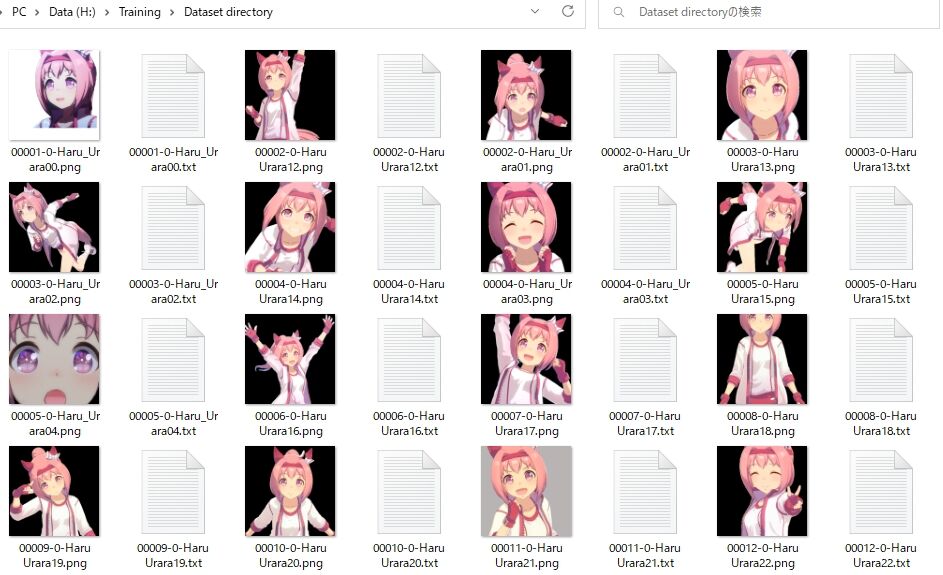
ここで次に行うのは、出力されたタグファイルの編集です。
例えば一番左上の「00001-0-Haru_Urara00.png」と対になるテキストを開くと、その画像を解析した結果、その特徴をとらえたプロンプトが自動で生成されて、列挙されています。
これも後で説明いたしますが、そのままだとほぼ確実に、大変なことになります。
これはある程度触ってみて仕組みが何となくわかってきたので言えるのですが、ここで記入するのは「Initialization text」で入れたハルウララの絶対的な特徴以外の部分です。
ですから「Initialization text」に入れた語は、ここでは省きます。
そして服装やポーズ、構図や塗りの特徴、表情などこの絵としての特徴を付け足す形になります。
この作業が割と面倒で分かるまでは大変なので、一番時間がかかります。
お試しでやるなら、数枚にとどめておいて、色々と試行錯誤してみるのが良いかと思います。
私は数枚(4枚)から初めて、意味が分かってきたらその都度付け足しつつ増やしていって、この状態になってます。
この絵とテキストの内容を突き合わせるの作業が凄く大事っぽいので、ここは手を抜かずやりましょう。
④ トレーニング開始!(Train)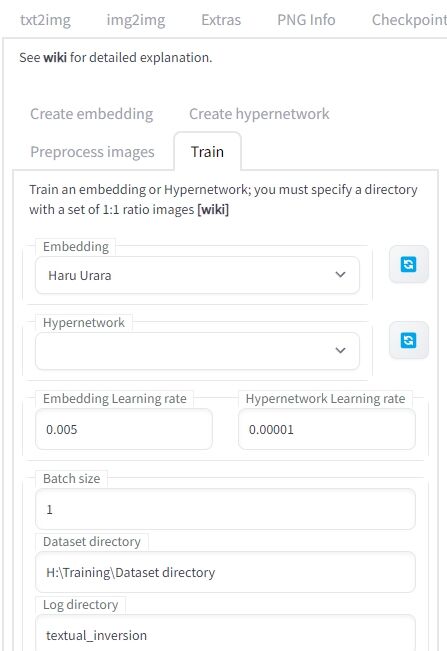
「Embedding」は、先ほど①で作ったものを指定します。
複数作っているなら、トレーニングするものを選びます。
今回はオフラインでやるのと、ハルウララと言う新しい概念を植え付けるので「Hypernetwork」は使いません。
また、トレーニングするモデルは、今現在選ばれているものになります。
今回は「wd-v1-3-float16」を使用しました。
「Dataset directory」に先ほど作ったテキストファイルと対になっている学習用素材の入ったフォルダを指定します。
学習素材用のフォルダ名をそのまま「Dataset directory」にしておけば間違えないですね。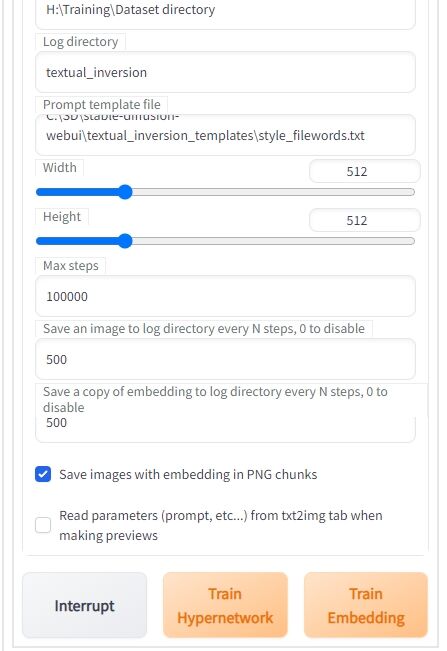
後は「Max steps」を指定します。
デフォルトが10万なので、ここは注意してください(見逃した人)。
とは言え、「Interrupt」ボタンで止められますので、間違えてもあわてずに止めて再設定しましょう。
最初は1万位で様子を見つつ、必要なら増やしていくのが良いと思います。
「Embedding」を変えない場合は、2回目以降はそのステップ数を引き継いで開始されます。
例えば、1万ステップまで終わった「Embedding」を使用して更にトレーニングする場合は、1万より大きい値を指定しないと「もう終わってるんだよ、ボケが!」って突っ込まれます(そこまで酷く無い)
その都度、学習させる内容も変えられますので、色々と試して進めていくのも良いかもしれませんね。
とりあえず学習させるだけなら後の数値はいじりません。
と言うか面倒なので私はいじりませんでした。
※1月18日 11:56追記
コメント欄でご指摘いただいて気が付いたのですが、この時のトレーニングでは「Prompt template file」に「style_filewords.txt」を使ってしまっています。
これは画風をトレーニングするものなので、今回のようにウララ個人の概念をトレーニングする場合はこの部分を「subject_filewords.txt」に変えましょう。
最後に「Train Embedding」ボタンを押して、トレーニングを開始しましょう。
後は待つだけです。
以上、簡単ではありますが最低限のトレーニングに必要な操作でした。
おいでませ!ハルウララ! と思ったが?
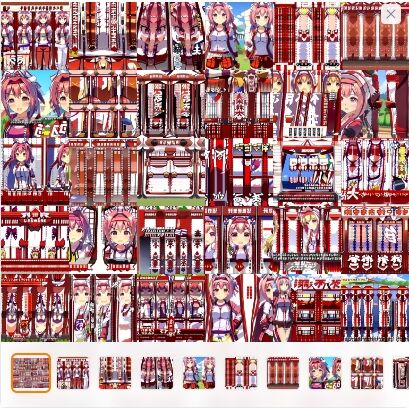
さて、では、ここからは実際に私が四苦八苦しながらトレーニングを進めていった過程をまとめておきます。
既にこちらの記事やブログを読んで下さっている方はお分かりかと思いますが、私は基本的にものぐさな人なので「とりあえず動かしてみればいいのよ」を地で行くことが多いです。
いや、何となくわかった気になるんだけど、触って動かしてみないと腑に落ちないタイプの人間なのですよ、ええ。
で、今回もそういう訳で、とりあえず動けば何でもいいや、とばかりに最初のトレーニングをしました。
初期は4枚だけを使い、設定もほとんどいじらず「Initialization text」も*(アスタリスク)のまま、動くじゃーん、よっしゃーとばかりに10万ステップほどトレーニングしてます(計14時間)
仕事を出る前に仕込んでそのまま仕事をして帰ったら爆睡し、朝に確認したのでどうなってるかなーと思ったら上の通りです。
「ひぃ、なにこれー!?」って感じで、多分、何も知らない人がトレーニングしたら必ずと言っていいほどこうなるんじゃないかな? 多分。
とりあえずよくわからんまま順を追っていくと、色々と見えてきました。
まず、初期は割と普通に学習していきます。
まぁ、何かよくわからんけど悪く、無い? 一応、ウララに見える!
しかし、ステップ数が5万を超えたあたりから……
何でか文字が入り始め、分裂を繰り返すように。
ところどころ、何かよさげな感じもあるんですけど、なんか怖い、怖いよ!?
ひぃ!? ナニコレ。どうしてこうなった!?
と言う感じで、初回のトレーニングはクリーチャーを世に放つ結果となりました。
この時点ではまず、そもそも使い方が全く理解できておらず、何となーく動かしてたので、今にしてみればそりゃそうだよなーと。
そして、調べた結果、凄ーく参考になったサイトがこちら。
いや、本当に参考になりました。凄くわかりやすかった。ありがとうございました!
このサイトを見て、改めて細かい設定方法とかが間違っていたことに気が付き(遅い)、修正しつつトレーニングを最初から進めました。
初期を4枚として、背景を消し、更に「Initialization text」も設定。
初期3万まで進めたところで、こんな感じでした。


悪くない、んだけど、何か変。何だろ?
そこで「Initialization text」に服が入ってるのが悪いのか?という事に思い至り、修正し更に上澄みしつつステップを積み増します。


悪くはない! 若干おかしい部分もあるけど、一応、ハルウララっぽい!(ぽいだけ)
ただ思ってたよりお姉さんよりに描写されていたので、最終的には「small_girl」を入れてみて、更に全体像を加えて更にトレーニング。
うーむ、思ったより安定しない。
とりあえず、この記事の時点では10万ステップになったところでいったん止めてみました。
多分、体を入れている絵が何か悪さをしてるっぽいんですよね。
途中で切れている構図が多いので、それを学んでしまっているかも?
顔は顔だけでトレーニングして安定するまで回した方が、もしかしたらいいのかもしれません。
この辺りはちょっとわからない事が多いので、手探りで色々と試しつつですね。
また、各ステップでどの位違いが出るのかちょっと試してみたのでご紹介しておきます。
なお、デフォルト状態でトレーニングをすると、500ステップ事にイメージと「embeddings」が出力されます。
もし仮に特定のステップ数の描写を試したい場合は、以下のようにします。
① 作成されたステップ数のファイルを以下のフォルダから探す
「stable-diffusion-webui」→「textual_inversion」→「日付」→「embeddingsでつけた名前」(今回はHaru Urara)→「embeddings」
例えば今回の場合、4万ステップのembeddingsが欲しい場合は、「Haru Urara-40000.pt」ファイルを探す。
② そのファイルを「stable-diffusion-webui」→「embeddings」フォルダ内にコピーする
既にHaru Urara.ptが存在しますが、これはマックスまですすんだptファイル(今回は10万)なので、そのまま置いておく。
③ txt2imgタブでプロンプトに「.ptを省いたファイル名をそのまま」使用する
今回の場合は、4万ステップのファイルは「Haru Urara-40000.pt」なので「Haru Urara-40000」と入れればそれを使用した絵を作ろうとします。
embeddingsのデフォルトである「Haru Urara」を入れれば、そちらを使用して絵を描こうとします。
割とこの使い方の部分の説明が私には探せてなかったので、上記の記事は凄く参考になりました。
と言う訳で、以下のプロンプトを使い、シードも同じにした場合、どういう絵になるかを比較しました。
プロンプト
solo, 1Girl, Japanese Anime of a Beaultiful Girl, Beautiful Composition, Cinematic Lighting, pixiv, Light Novel, Digital Painting, Extremely Detailed, Sharp Focus, Ray Tracing, 8k, Cinematic PostProcessing,smile Haru Urara,
white_background, symmetrical perfect face,upper body
ネガティブプロンプト
mutated hands and fingers, text, title, deformed, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, malformed hands, out of focus, long neck, long body, multiple_girls, bad_anatomy, bad_hands, quality
〇 50,000ステップ
全体的にやや、崩れ気味でちょっと書き込みが甘い感じです。
あと「Initialization text」に「small_girl」を入れて浅い時期だったせいか、大人びた感じの絵が多いです。
ちなみに、このステップだと、ちょっと大人っぽい画風になるせいなのか割と面白い絵が取れてます。
「お姉さま、あれをやるわ」
ええ、よくってよ、みたいにしか見えない感じのものがあったり。
ウララ、稲妻っとけ(何
〇 76,000ステップ
何だか少し体が不安定に。一方で、顔の描写は割と細かいところまで行けるようになってます。
ところどころ崩れているのはご愛敬?
〇 100,000ステップ
体さえ描かせなければ、かなり安定してきたステップです。
まだ首の部分とか体の部分がかなり怪しいのですけど、顔に関しては割とバランスが取れてきた印象。
何より少しだけ幼さが戻ってきて、ウララっぽくなりました。
現時点ではこんな感じで、とりあえずウララだ!ってなる位には洗練されてきたかなと思ってます。
一方で体の描写がとても苦手でして……
上半身までなら割とSSR級の良い感じの絵が出ることもあるんですけど
やはりクリーチャー率が異様に高く、
腕が無くなったりゆがんだりするのはまだよくて、
どちら様? むしろ生物? みたいになることも多いです。
後は遠目で見ると悪くなかったりするのですけど、コラ画像化している頻度は増えます。
これは精度が上がると、徐々にこなれていく印象がありますね。
なのでステップ数を増やすことで、馴染ませていくっていう効果はあるんじゃなかろうかなーと。
ただ、やみくもに学習数を増やしてもいずれ破綻していくようなので、どの辺りでやめて、別のアプローチをしてみるかと言うのが難しそうです。
以上、現段階に至るまでの私の忘備録でした。
総評 思ったより難易度が高いので今はお勧めはしない
私は割と時間がある方なのと、試行錯誤は好きな研究者肌なので良いのですが、これを一般の、しかも初心者の皆様がやるのは、現時点ではあまりお勧めできないと思いました。
そう思った理由はいくつかあるので、以下にまとめます。
① トレーニングさせる環境を用意するのが大変
私のようなPC主体に活動されている方は、既にハイスペックの物をお持ちの方もいらっしゃるでしょうが、大抵の方はそんなハイスペックなPCは無いと思うんですよね。
特に絵描きの方は、低スペックやミドルスペックで満足しちゃうようですし、ゲーマーでもない限り、そもそもこのスペック群のPCは持ってませんよね。
なので、よほどのお金持ちや興味のある方以外は、スタートラインにすら立てないのが現状です。
ちなみに、参考までにですが、私のPCを市販でゼロから買うとなるとこんな感じ。
ただし、グラボは一つ下の3060の12Gなので、若干値段は下がるかもしれません。
ただその構成の物があるかどうかはわかりませんし、3080Tiの方がより安定的に使える可能性もありますので、参考程度にお願いします。
※2022年12月22日 更新
いつの間にか3060の12Gを搭載したバージョンが販売されてました。
メモリとストレージがやや不安があるので、そこを強化すれば3年は戦えるPCかと思います。
勿論、私の使っている環境とほぼ同じなので、問題なくAIちゃんもトレーニングできるはずです。
気になっている方は、参考にしてみて下さいね。
② 仕組みや使い方を理解するのが大変
今回は「Stable Diffusion web UI」に組み込まれた「Textual Inversion」の機能を使っています。
なので、ぶっちゃけ「Textual Inversion」を理解していれば問題なかったのですが、そこに行きつくまでに遠回りしまくりました。
Wikiやら色々見てはいたのですが、実際に触ってみないとやはり理解するのは難しいですね。
私は特に体験して手触りで覚えていくタイプの人間なので、余計にそう思いました。
とは言え、今は翻訳が簡単にできるので、英語のページだろうが何だろうが、割と簡単に読めるようなったのはありがたいですね。
なので、環境が用意できたうえでヤル気と根性さえあれば、何とかなるとは思いました(いつも通り)
③ 語彙力が無いとそもそも無理
とは言え、このAI描画の根本的なところに語彙力が無いとそもそも描かせたい構図を指定できないというものがあります。
一応、辞典的なものはあるのですが、そもそもの言葉の使い方がわかってないと、プロンプトで指示するのも一苦労だと思います。
ましてや、トレーニングはその逆で、覚えこませる単語を列挙しないといけないので、ある程度の語彙力が無いとAIちゃんも困るらしく、スッカスカになってトレーニングが破綻します。
特にトレーニングは新しい事を紐づけする作業なので、どんな絵を用意してどんな言葉を紐づけるかだけで、かなり精度が変わってきます。
それは私の記事を読んで頂いた皆様なら、ある程度、察しが付くでしょう。
巷では、AIを使えば簡単に絵を描けると勘違いされている方も多いでしょうが、触ってみた方ならお分かりかと思います。
確かに何でもいいならそれっぽい絵をすぐに出せます。
ただ、自分の思い通りに絵を描くのは至難の業ですよ。
それこそ、異なる技術体系が必要なくらいに難易度が高いので、私はこれも一つの技術だと思っています。
この辺りはいずれ改善されていくでしょうが、今の時点ではそういう異なる方向での技術の壁があるので、私のような文章を得意とし、かつプログラムにある程度精通している方なら、おススメできると思います。
今回はウララをトレーニングさせましたが、絵師の皆様ならご自分の絵を覚えさせて使う事になると思います。
ですが、狙った構図を作り出すのが難しい上に、背景が制御しにくいなど、問題もあるため、今の時点ではまだ十全に活用するのは難しそうだというのが私の感想でした。
ある程度お金のある方は、商業用に用意されたものを使って精度の高い技術を活用した方が時間的には宜しいかと思います。
一方で私のような探求心を持っている方で、コソコソと(?)色々と(?)やりたい方は、面白い技術であるとは感じています。
実際、AIちゃんが試行錯誤している様子が肌で感じられるので、何となく愛着がわいてきますよ。
おお、そうか、そういう風にしたのかー、あれ、そうなっちゃう?ダメな子だなぁーもうーみたいな感じで、育ててる実感がわいてきます。
何より、「ウララ(を描くAI)は、私が育てた」(ででーん)
みたいな感じになれるのが凄く楽しいです(小物
そして、そこをどうやって調教……じゃなくて、教育していくかが腕の見せ所になるので、色々と試行錯誤すること自体は楽しいです。
そんな感じで、私のように楽しみたい方は、おススメできますが茨の道であることはお覚悟ください。
自分の絵を作り出してみたいなと思っている紳士淑女の皆様の力に少しでもなれたらなら幸いです。
けど、重ねて何度も申し上げますが、人の絵は勝手に使っちゃダメですからね?
※2024年 4月5日 追記
この記事の続きの物も書きました。Dreamboothの使い方の記事です。
また更に進化して、LoRAも扱えるようになってます。
もしご興味があれば、こちらもどうぞです。
今回の記事は以上になります。
お読みいただき、ありがとうございました。


コメント
おっすおっすくれすさんだよ。
やっぱこの技術って難しいけどおもしろいモンなんやなあ。
ウララだけを学ばせるにしてもこの苦労、現状しっかり使いこなして思い通りの絵を出力できている人の努力が垣間見えるんだなも。
私個人としては、確かにチートに見えなくもないけど、そこまで忌避するような感じもないかなあ。
自分の絵を学ばせても自分が描きたい絵は出てこなさそうだしね。
アイデア出しのサポート機能って考えるなら3Dデッサン人形と近しい存在になっていくような気がする。知らんけどな!
>>1
くれすさんへ
おお、こんにちはー
相変わらずこの微妙な立ち位置の記事にコメントありがとうございます!
いやぁ、流石に私のレベルでは仕組みや原理等は良く分からんのですが、とりあえず触って遊べるくらいまではいけるようになりました
触れば触るほど面白い技術だと思ますが、くれすさんのおっしゃる通り、思い描く理想の絵を出そうとすると今の時点ではかなり無理ですね
なので、巷でAIを駆使して凄い絵を出してる人は、それはそれで凄い事なんですよ
ただ絵そのもので考えれば確かにチート級なので、それは同感ですし絵師さんの気持ちを考えると色々と配慮は大事だなと思います
くれすさんの作品は、筋が通っていて描きたいものを描いていると私は感じておりますのでそういう方は、あまり気にしないと思うんですよね
ある意味それはオンリーワンですし、絵を描く技術が自分の信念によっているので、AI云々で揺らぐものではないでしょうし
あ、そうなんですよ
多分、くれすさんの絵を学ばせてもまんまで描けるわけではないんです
もし次の記事を書くならその辺りにスポットを当てて書くことになりますが、モデルの癖によって表現できる絵に幅がありますね
ただ、デッサンやラフ、線画なんかはかけるみたいなので(トレーニングは必須ですが)、そっち方面で特化してそこから自分の絵に仕上げていくとかいうやり方や、逆にラフからある程度の段階まで一気に仕上げることができるツールには、いずれなると思います
あとは自分が描くのが得意でないところを埋める感じには使えそうですね
背景やオブジェ、画面の効果何かを付け足すには凄く良いと思まスよ
ではではー
トレーニング時のprmpt template file を
style_filewords(画風用)ではなく同ディレクトリ内のsubject(被写体用)にすればいいっぽいですよ
>>3
全治2ヶ月さんへ
おっと、こんにちはー&初めまして。
このような辺境&初心者の記事にコメントありがとうございます。
なるほど! 何もわからず、とりあえず初期設定でやってましたが、一応描写は出来ていたので気にしてませんでした。
確かに全治2ヶ月さんの仰る通りFileWordsの種類を変えた方が、トレーニング効率は良くなりそうですね。
今はDBの方で試行錯誤しているのですが、思ったようにはならなくて、記事を書ける水準に達するまでにはまだまだかかりそうです。
そもそも使い方がよーわからんのよ……何で少し目を離すとUIごと変わっちゃうのかなぁ!?
そして、昨日まで問題なかったのに、さっき起動したら何かログイン求められますね。
Twitter情報だと、どうやら開発者のアカウントが消されたので、移動したとの事。
ちょっと現状はなりすましも含めて怖いので、少し様子を見て情報を集めてからまた機会があれば再開したいと思います。
と言う感じで情報ありがとうございました!
次の記事がいつになるか、更に不明瞭になりましたが、又何かあれば突っ込んでやって下さいな。
ではではー。
絵師もAIも学習のやり方は同じですよ。絵師も他の絵師のマネをして成長しますから。0から描いている人はいません。
>>5
yamatoさんへ
こんにちはー&初めまして!
貴重なコメントありがとうございます
yamatoさんの仰られる事は、私もそうだと思っていますので肯定致しますね
ただこのコメントからyamatoさんが何を伝えたかったかはちょっと私には読み取れませんので想像で返信させて頂きます
恐らくなのですけど、yamatoさんはAIを活用し肯定される方で、この記事の絵師さまに配慮した部分に引っ掛かってこのコメントを残したのかな?と私は推察いたしました
重ねて申し上げますが、yamatoさんの仰ることは私も肯定しますし、事実その通りだと思います
ですが、となってしまうんですけど、ひるがえって絵師さんがそれを納得できるかどうかは話が別なんですよね
特にモデルの作成に関しては怪しい部分も多く、現在では野放しの状態です
自分の絵がモデルに勝手に使われ量産されている事をよしとしないのもまた感情としては当然でしょうね
この辺りは正直に申し上げて法的にどうなるか、でかなり変わるでしょう
今の時点では法整備が追い付いていないだけなので、変わった後にどうなるか分かりません
なので嫌だと言っている絵師さんの絵が入っている可能性のあるモデルを使うのも後々のリスクがありますし、それを絵師さんに頭ごなしに許容しろと言うのも筋が違うと思います
逆に使ってもいいよーという絵師さんの絵を使ったクリーン(ここでは著作権的に問題なしとします)なモデルで楽しむのは私も良いと思います
そういうクリーンなモデルで発展していければ、お互いに嫌な思いをしなくても良いんですけどね
私としては絵師さんも納得できて、AIを使う側も気持ちよく創作できる土壌が出来てくれればなぁと願ってやみません
とまぁ、私の感想としてはそんな感じです
yamatoさんの主張したい事とずれてしまってたらごめんなさいね
では、貴重なご意見有難うございました