
皆さま、こんばんは。
このような辺境まで、お越し頂き、ありがとうございます。
Twitterやネットでの情報を追っている皆様は既にご存じかと思いますが、日々、画像描画AIの進歩が止まりません。
一応、今は画像描画AIの祖ともいえる「Stable Diffusion」だけでなく、沢山のモデルが世に出ておりますが、私は敬意を表して今後も描画AIの事を表す言葉として、Stable Diffusionとして語りたいと思います。
で、そちらを何とかローカル環境で使おうと奮闘したのが、前回までの記事の内容になります。
いやぁ、相変わらずわからない事だらけで苦戦しております。
そして何度も書いておりますが私のやっていることはあくまで基礎レベルなのですが、毎日のように一定数の迷い子達が訪れてくれておりまして、相変わらず私が思ってもみなかったレベルで読まれているようです。
流石にトレーニング系の記事が続いたことと、PC初心者の皆様にはハードルが高い事もあって、前よりは減ったかな?と言う印象です。
ただ皆さん、気にはしているし潜在的な需要自体は非常に高いんだなぁという事を改めて感じます。
そこで、今回はやっと本命にあたる絵師さんに送る記事を書きました。
前回でトレーニング(ファインチューニング)という、ある意味禁忌の扉を開ける記事を書きました。
それは、記事に書いた通り避けて通れない事だと改めて私が感じた上で、その技術を特に絵師の皆様にちゃんと知っておいて欲しいと感じたからです。
そしてそれを何で先にやったかと言うと、自分の絵柄や求めるキャラを作るのに描ける方が自分で描いて覚えさせた方が楽になると私が感じているからです。
今回はそんなトレーニングの下地が終わった場合を含めて、まだこの時点でAI描画に触れたことのない絵師様に向けて、一つの活用方法をご提示したいと思います。
そんな感じで今回も語りながらも相変わらずのポンコツな私が使用できるようになるまで苦労したことや、思うところについて書き残しておきたいと思います。
【注意】
今回は、再描画のお話になります。
ご自分の絵や写真を元に使うのなら良いのですが、人の絵を使う場合は、絵師様の許可はとりましょう。
著作権や絵師様への配慮等、様々な問題に絡みますので、くれぐれもこの技術の使用には細心の注意をもって対峙して下さい。
また、この記事は主に、プログラム関係に馴染みのない方に向けて作成しております。
私はあまり知識が深くないので、今回も凄ーくどうでもいい事で苦労していますので、既にその手の方面に知識のある方には理解できない部分で躓いているためイラっと来る人もいらっしゃると思います。
知識の深い方には、素人が右往左往する姿を楽しむ位しかできない記事かと思いますので、そのつもりでお進みください。
また、最近のAI技術の進歩が速すぎて、サクッとこの記事の内容が古くなる可能性が高いです。
その点を念頭に置いた上で、お楽しみくださいませ。
Stable Diffusion web UI(AUTOMATIC1111版)をローカルにインストールする方法

nn最近、後述を致しますControlNetの登場で、Stable Diffusion web UI(AUTOMATIC1111版)を使用したいと思う方が増えてきているようです。
実は、今回の記事の様にトレーニングを介さないで使用する場合は、そこまでマシンパワーを必要としません。
一番最初に書いた記事から、状況もだいぶ変わってきましたので、これを機に今一度、Stable Diffusion web UI(AUTOMATIC1111版)の使用要件を確認しておきたいと思います。
基本的な使用要件の確認
まずは、ご自分のPC環境でStable Diffusion web UI(AUTOMATIC1111版)が動作しそうか、確認しましょう。
最も重要なのは、VRAMが最低4G以上(可能であれば6G以上)という事です。
今回は、Windowsの調べ方を置いておきます。
VRAMさえ確保できていれば、MacやRadeonでも動くっぽいので、調べてみて下さい。
仮にVRAMが足りない場合は、どうあがいてもそのPCの能力では無理です。
また、OSやグラボの環境によってはやはり無理なので、その場合はGoogleアカウントを作ってColabのお世話になりましょう。
こちらのサイトがやり方を詳しく説明してくれているので、どうしても使ってみたい方は参考にしてみて下さい。
ただし、ローカル環境に勝るものは無いので、もし資金に余裕があるならPCやグラボ購入も視野に入れて見て下さいね。
さて、6G以上のVRAMを実装しているPCの皆様は次へ進む希望が持てます。
ちなみに私の現環境はこちら。
・CPU
Core i7-12700

・OS
Windows 11
・メモリ
48G
・私の知識レベル
Java ScriptやGASなら書けるくらい
Python?最近流行ってるよねーくらい
開発環境? 何それ美味しいの?(テキストベタ打ち)
AIを楽しむために、ジワジワとスペックアップして今に至ります。
グラボが1660Super(6G)だったので、それでギリギリ動く環境でした。
よほどのお金持ちや興味のある方以外は、スタートラインにすら立てないのが現状です。
ちなみに、参考までにですが、私のPCを市販でゼロから買うとなるとこんな感じ。
メモリとストレージがやや不安があるので、そこを強化すれば3年は戦えるPCかと思います。
勿論、私の使っている環境とほぼ同じなので、問題なくトレーニングできるはずです。
ただ、技術が進んで使用メモリ量を削減できるようになれば、もう少しグラボの選択肢は広がると思います。
買い替えを検討している方は、参考にしてみて下さい。
トレーニングを使わずに出力だけで楽しむ場合は、解像度を上げなければ8Gあればなんとかなると思います。
ただ、AIで活用するにはVRAMはあって損はないので、今後の事も見据えて多めのもので且つスペックの高いグラボを選ぶのが理想でしょう。
トレーニングをしない場合、私の使っている3060以上(数字が上)なら、基本問題無いと思っていいです。
トレーニングをするなら上記に加えてVRAM12G以上のグラボを検討して見て下さい。
では、話は長くなりましたが、環境構築について前の記事から引用です。
内容自体は変わってないので、読んだことのある方は飛ばしてください。
最近は、他のサイトでもインストール方法を紹介している記事が増えてきた印象です。
なのでこちらでは、そう言った記事のご紹介と、簡単な設定方法だけ再度、書いておきたいと思います。
まず、うちの超見ずらい(自覚はある)サイトよりは、とても良い記事がありました。
モデルの紹介もありますので、基本はこちらのサイトで見ていけばいいかと思います。
では、その上で一応、こちらのサイトでも軽く書いておきますね。
とりあえず、注意点としては前の記事から変わらず、以下の部分です。
① Pythonは3.10.9を使いましょう
実は新しいバージョンで3.11.0が来てるのですけど、そちらだと上手く動きませんでした。
多分、ソースでバージョンを縛る部分があるっぽいです。
なので、3.10.9を選んでインストールしましょうね。
ちなみに前回の記事では3.10.8で紹介していましたが、バージョンが上がっていたので一応、こちらに差し替えてます。
とりあえず問題なく動いているっぽいので、どちらでも良いかなーとは思います。
〇 Download Windows installer (64-bit)
インストールの際には、下部の「Add Python 3.10 to PATH」にチェックを入れる事をお忘れなく。
最悪間違ったらアンインストールからの再インストールでもOKです。
② Git は最新のものでOK CUDAは必要なし

前回の記事ではCUDAも入れるようにご案内しておりましたが、どうやらWebUI側で対応したらしく、PCへ個別に入れる必要はなくなりました。
上手くインストールできたか確認したい場合は、コマンドプロンプトで以下のコマンドを使ってみましょう。
コマンドプロンプトの起動方法が分からないという方は、以下のサイトを参考にしてみて下さいね。
簡単に説明すると「Windowsキー(四つの🔲が集まったマーク)」+Rで「ファイル名を指定して実行」を開き、「cmd」と入力します。
〇 Ptythonのバージョン
python -V※注 Vは大文字
なおコマンドをこちらでコピーしたら、コマンドプロンプト上で右クリックすることでペーストできます。
なお、コマンドプロンプト上の文字をなぞって色を付け右クリックをすると、その文字列をコピーできます。
貼り付けた後、エンターキーで、コマンドを実行できますので、覚えておきましょう。
〇 nvccのバージョン
nvcc -V〇 gitのバージョン
git --version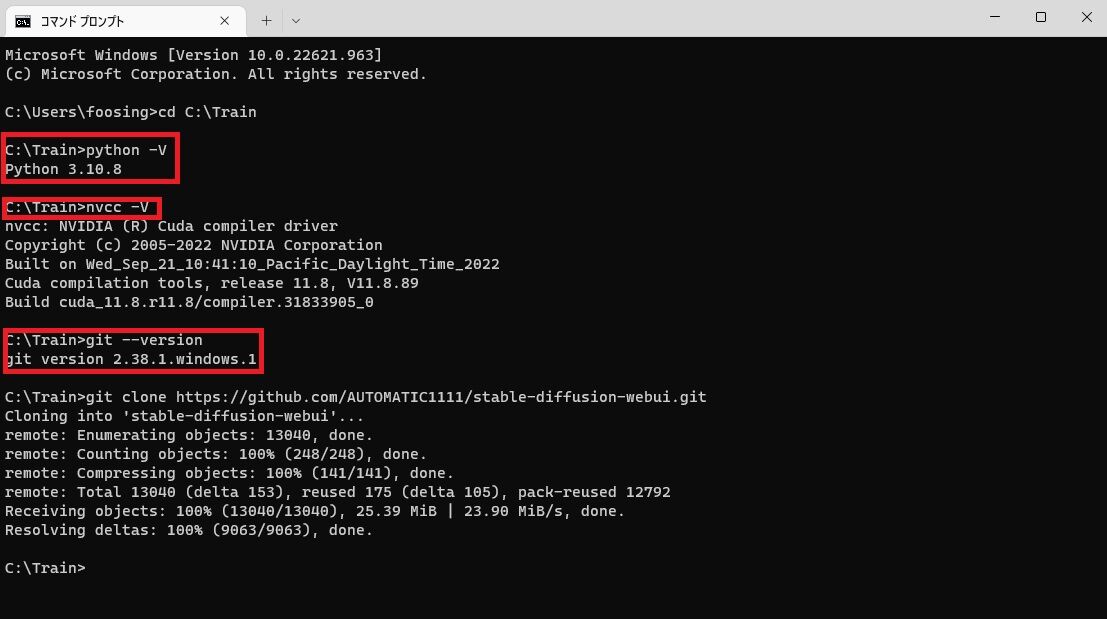
① Stable Diffusion web UI(AUTOMATIC1111版)をインストール
まずはStable Diffusion web UI(AUTOMATIC1111版)をインストールするのですが、実は今はめちゃくちゃ楽です。
まず、インストールするフォルダを作っておきましょう。
今回はCドライブ直下にTrainというフォルダを作りました。
C:\Train
コマンドプロンプトを起動し、その場所に移動します。
cd C:\Traincd(スペース)ファイルアドレス
前の記事で書いたように、エクスプローラー上でファイルの場所を右クリックして「アドレスをテキストとしてコピー」をした後、コマンドプロンプト上で右クリックするとその場所を貼り付けられます。
cd を前に書いてファイルパスを貼り付けたあと、エンターキーを押しましょう。
C:\Train>
※ファイルの場所
となっていたら準備OKです。
以下のコマンドをコピーして貼り付けエンターキーを押します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webuiインストールが始まり、Train(指定したフォルダ)内に「stable-diffusion-webui」フォルダが作成されているはずです。
② モデルの配置
その後は、モデルを配置します。
C:\Train\stable-diffusion-webui\models\Stable-diffusion
上記のフォルダにモデルを入れておきます。
普通のファイルのようにダウンロードしてきて、コピー&ペースト(もしくは移動)でOKです。
今回は「wd-1-4-anime_e1」を置いておきました。
モデルが無いという方は、先ほど紹介したサイトから追うか、Wife1.4を使う事をお勧めします。
「」と「」の両方が必要です。
この二つを上記フォルダに配置しましょう。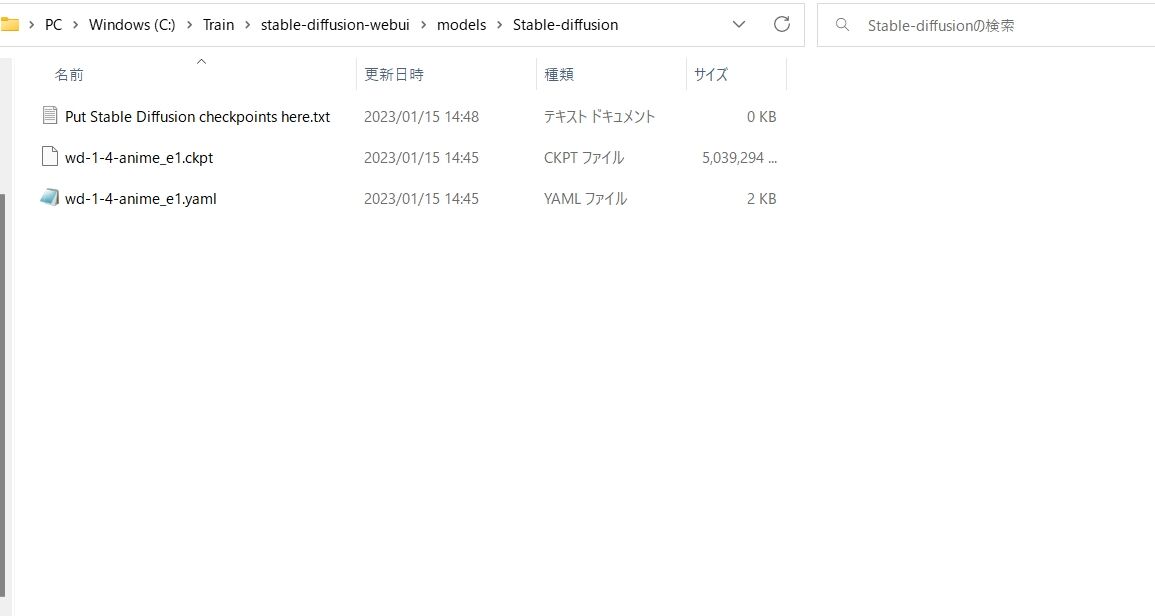
※実はこの記事を書いている最中に、更に新しい「」が来ております。
なので、そちらを使っても良いと思います。
その際、yamlファイルは上記の物を落として、名前を「wd-1-4-anime_e2.yaml」に合わせましょう。
③ webui-user.batから起動する
なお、起動batである「webui-user.bat」内の「COMMANDLINE_ARGS」に以下の設定をしておきましょう。特に、VRAMに余裕のない場合は、必須項目です。
トレーニングする際にも、ほぼ全てのPCで必須なので設定が必要です。
「stable-diffusion-webui」フォルダ内の下の方に「webui-user.bat」というファイルがあると思います。
右クリックで編集を選択し、メモ帳などで開きます。
Windows11は編集が隠れておりますので、Shiftキーを押しながら右クリックをしましょう。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers
git pull
call webui.bat
ちなみに「git pull」を入れておくと「webui-user.bat」で起動した際に、更新をかけてくれるようになります。
最新状態にしておきたい方で、私のようなものぐさな人は入れておきましょう。
逆に、環境をなるべく変えたくない人は入れないでおきましょう。
「webui-user.bat」をダブルクリックして起動します。
起動は「webui.bat」ではなく「webui-user.bat」ですのでお間違いないように。
起動すると新しいコマンドプロンプトが立ち上がり、暫く固まります。
見た目には動きが少ないので心配になりますが、そのまま根気強く待ちましょう。
最後の方に「http://127.0.0.1:7860」等のリンクが出ればOKです。
コマンドプロンプト上のリンクを「ctr」を押しながらクリックすれば、すぐに開くと思います。
仮にエラーが出て止まった場合、大抵の場合はモデルの配置忘れです。
正しい場所にモデルが配置されているか、確認しましょう。
これにて基本構成の構築は終了です。
ただ使うだけならばこれで十分なので、使いたいだけの方は参考にしてみて下さいな。
起動は出来たが、画像出力ができない場合
VRAM的に余裕がない場合や古いグラボの場合は単純にスペック不足である可能性が濃厚です。
その場合は、描画時間を犠牲にして無理やり動作するオプション群が備わっています。
英語やPCの苦手な方も多いでしょうから、簡単にかいつまんで説明すると「webui-user.bat」内の「COMMANDLINE_ARGS」に追加で「–medvram」の設定をしておきましょう。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --medvram
git pull
call webui.bat
試しに今の環境で動かしてみましたが、ギリギリ4Gを超えるか超えないか位の感じでした。
512×512の解像度なら、多分、問題なく動くと思いますので、試してみて下さい。
※2月19日 15:15追記
Twitterを見ていたら、4Gでの動作を試してくれている方がいらっしゃいました。
#StableDiffusion で #ControlNet の実験をやっていた。VRAM 4GB環境。–medvramだと落ちる。–lowvramだと実行可能。ただ時間がかかる。

との事なので、もし「–medvram」でもダメな方は「–lowvram」に書き換えて、試してみて下さいな。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --lowvram
git pull
call webui.bat
絵をブラッシュアップしてみよう(img2img編)
Stable Diffusion web UI(AUTOMATIC1111版)にデフォルトで搭載されている機能の中に「img2img」と呼ばれるものがあります。
こちらは、初期のころより活用されてきたもので、今なお便利な機能として進化を続けております。
これは元ある絵をベースとしてプロンプトに沿った絵へと作り直すものです。
その為には元になる写真なり絵を用意しなくてはなりません。
なので、実際に使う場合は写真を加工したり、絵の一部を修正したり、txt2imgで出力した絵を修正するのに使ったりします。
さて、いつもならウララのスクショなどでお茶を濁すのですが、毎回それでは芸がありません。
また、実際に絵師さんの絵を使ってみた方が、イメージも沸きやすいでしょう。
そこで、今回はお友達の絵師さんにご協力を仰いだところ、快く賛同してくれましたので、以下の記事においてはその方の絵を使わせていただきました。
田中さんと言う絵師様で、とても味わいのある絵を描かれる方です。
絵を練習し始めてからずっと応援してきましたが、まさに田中風と言う感じの絵を体得しているので、今後が楽しみです。
田中さん、素敵な絵の提供を本当にありがとうございました!
では、まずはラフな絵をimg2imgにかけるとどうなるか、見ていきます。
〇 元の絵(エミリーちゃん)
試食をしているエミリーちゃんとの事で、こちらをAIで補正するとどうなるか見ていきましょう。
使用するモデルは「Elysium_Kuro_Anime_V1」です。
img2imgを使うには、その名の通り、img2imgタブを選びます。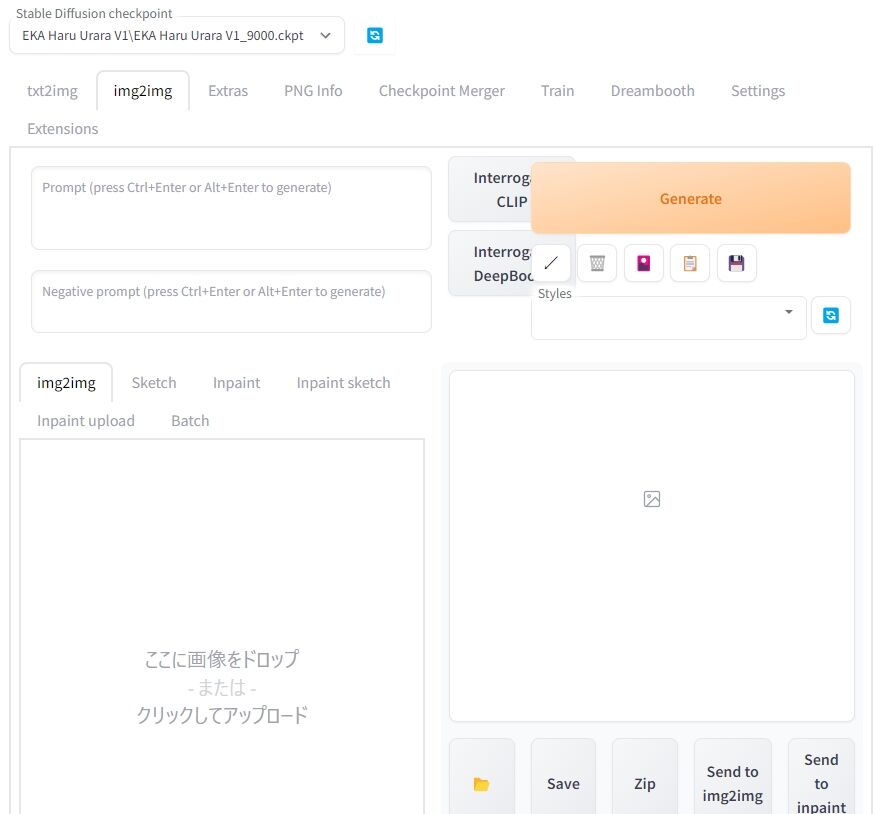
上の作りはtxt2imgとほぼ同じなので直感で理解しやすいでしょう。
プロンプトで変更を加える場合は、こちらに必要なプロンプトを入力していきます。

こちらに画像をドラッグアンドドロップで置いて読み込ませます。
こんな感じですね。
そして、img2img用のパラメータを方を設定します。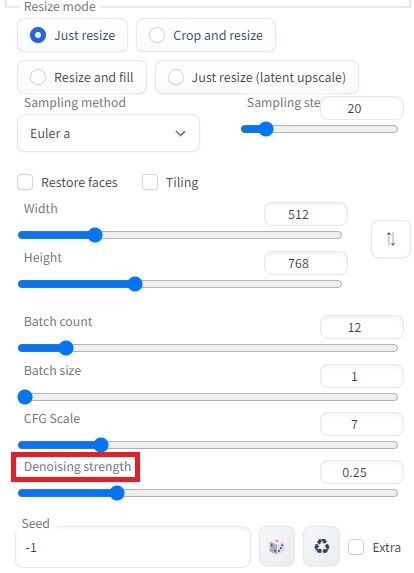
とりあえず重要なのは、解像度である「Width・Height」を元絵に合わせること。
そして「Denoising strength」で変化の割合を設定することです。
数値が大きいほど、元絵から離れていきます。
画面の0.25だとこんな感じになりました。
やや変化したかな?と言う感じで元絵をかなり踏襲した感じです。
ちなみに、もう少し変化をつけて0.40位だとこうなります。
割と変化して持ってるものや表情などもかなり変わります。
ちなみに、時間を節約するためさっくりとご紹介しておりますが、実はこれはプロンプト適用後の絵です。
実際には、プロンプトを何も入れないとこんな感じになります。
割と見れたものではないので、使い方が分からない方がいきなりやると、こうなる気がします。
実際に最初は少ないプロンプトから徐々に付け足したりして様子を見つつ、修正し増やしていく作業が発生します。
で、今回は、最終的に以下の様なプロンプトに落ち着きました。
・プロンプト
((masterpiece)), (((best quality))), ((ultra-detailed)), ((illustration)), ((disheveled hair)), floating, (((looking at the camera))), ((chromatic aberration)), ((caustic)), depth of field,light_leaks,finely detail,extremely detailed, ((an extremely delicate and beautiful)),glowing, pixiv style, trending on pixiv, japanese anime, (dark brown eyes), eat small food, Navy blue skirt, gray shirt, open mouth, hair band, white background
・ネガティブプロンプト(Elysium_Kuro_Anime_V1用)
(lowres:1.1), (worst quality:1.2), (low quality:1.1), bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry
img2imgで補正をかける場合は、動作や構図も含めて記入する必要があります。
その辺りが慣れてないと、かなり使いづらいので、大きく変えたい場合は、後述のControlNetの使用をお勧めします。
最終的に何度も試作を重ねて、個人的に気に入ったのがこの絵です。
田中さんの絵っぽい雰囲気を留めつつ、個人的に可愛いと感じる感じ仕上がってるかなぁと。
更にこの上の絵を元に、もう一度修正するとこんな感じです。
残念ながら私の腕では田中さんの絵の魅力を引き出すに至りませんでしたが、これはこれでありかな?と言う感じに落ち着きました。
こんな感じで、絵に修正をかけていくことで別の絵を生み出すという事が出来ますので、絵師さんにとっても面白いツールになるのではと考えてます。
ちなみに、同じような感じでエルダーフラワーちゃんの絵もいじってみました。
元の絵はこんな感じで躍動感に溢れる素敵な絵です!
この勢いを取り入れつつ、修正を繰り返し、プロンプトを変更し、試行錯誤した結果がこちら。
何とか雰囲気を残しつつ、綺麗目に仕上がったかなぁ?と言う印象ですが、どうでしょうか?
・プロンプト
((masterpiece)), (((best quality))), ((ultra-detailed)), ((illustration)), ((disheveled hair)), floating, (((looking at the camera))), ((chromatic aberration)), ((caustic)), depth of field,light_leaks,finely detail,extremely detailed, ((an extremely delicate and beautiful)),glowing, pixiv style, trending on pixiv, japanese anime, Light pink platinum blonde, Twin-tail pigtails, braided pigtails, long hair, golden eyes, open mouth, Documentary, Rolled bundle of paper popping out of Large green backpack, Brown leather first aid kit, white sling, put on a hood, Thin transparent white skirt with open front
・ネガティブプロンプト(Elysium_Kuro_Anime_V1用)
(lowres:1.1), (worst quality:1.2), (low quality:1.1), bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry
めちゃくちゃ大変だった……。
前回の絵もそうなのですが、どうやら「大きな口」を上手く認識するのが大変なようで、その辺りの調整や服の色とか、そもそも手に持ってるものは何なのか?みたいな構図の指定が語彙力的に大変でした。
そんな感じで、全体を一気に変える場合は、img2imgだと、バランスをとるのが、ちと大変と言う印象です。
ちなみに、指定した場所のみを変化させる「Inpaint」と言う機能もあるのですが、これはまたの機会に。
絵をブラッシュアップしてみよう(ControlNet編)
さて、今までのは実は割と前置きで、ここからが本題です。
そんな感じで田中さんの絵を元に、ああでもない、こうでもないと試行錯誤しながら記事を書いていた昨今において、突然、何の前触れも無く神機能が搭載されました。
それがこちらのControlNetです。
これの何が凄いの?と言う話なのですが、凄いのよ!(だからなに)
前述のimg2imgは、元の絵を踏襲すると言いつつ、割と構図などがブレる傾向にあり、使い勝手が今一つでした。
しかし、こちらのControlNetは、構図をそのまま残しつつ上書きできるようになってます。
極端な話、棒人間があれば、構図を作ることができ、トレーニングで自分の絵さえ覚えさせていれば、そのまま理想の構図で出力が可能な時代に突入したという事です。
ヤバい、本当にこれはヤバい。
モーションキャプチャーの絵版ですね。
では、まずは、導入方法から簡単にご紹介していきましょう。
Stable Diffusion web UI(AUTOMATIC1111版)でControlNetをインストールする方法
実はそんなに難しく無いですがちょっと面倒くさいので、私の見ずらいページより他の所が良いかなと思います。
と言う訳で、こちらをどうぞ。
とは言え、一応、簡単にですが、説明してきますね。
「Extention」タブにある「Available」から「Localization」にチェックを入れて「Load from」ボタンを押します。
以下のような画面が出ると思いますので「sd-webui-controlnet」の右にあるInstallボタンを押しましょう。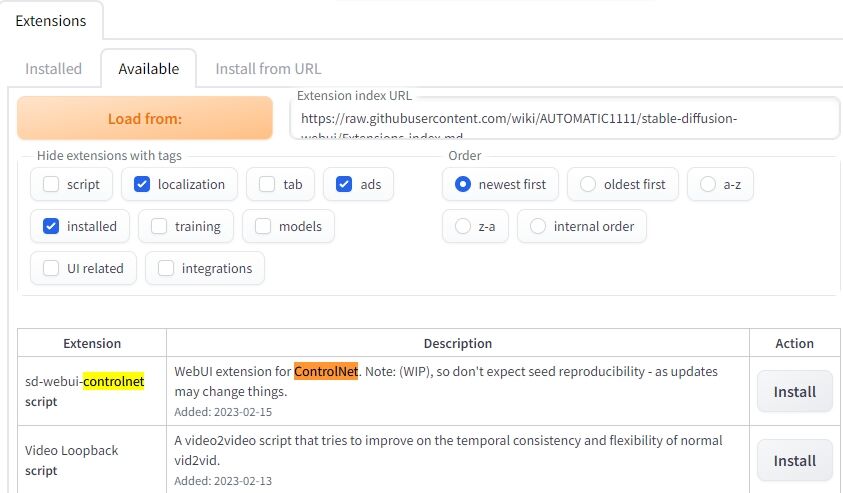
見つけられない場合は「Ctr+F」で検索画面を開いて「ControlNet」で検索してみるのが良いと思います。
右側のInstallボタンを押すと、コマンドプロンプト上で処理が走ります。
最初は何も動きがありません。気長に待ちましょう。
いつの間にか処理が終わり、項目が消えてると思います。
「Extention」タブにある「Installed」を確認して、そこに「sd-webui-controlnet」の名前があればインストール作業は完了しています。
そうしましたら、コマンドプロンプトをいったん閉じます。
Ctr+Cで止めた後に、Yを押して閉じるか、そのまま右上の×ボタンで閉じてしまいましょう。
その後、再度「webui-user.bat」をダブルクリックして起動します。
問題なく起動していれば、txt2imgとimg2imgタブの下に新しく「ControlNet」の項目が出来ているはずです。
しかし、このままではまだ使えません。
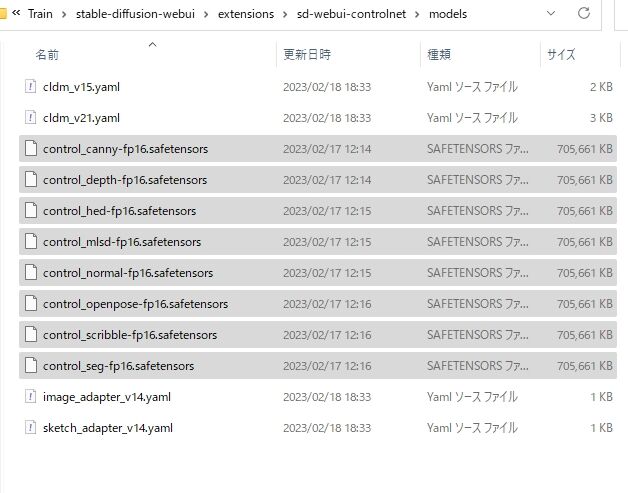
各機能に対応したmodelを手に入れる必要があります。
モデルは機能ごとに分類されておりますが、とりあえず8個全部落としましょう。(700M位のファイルです)
こちらのサイトから手に入れられますので、必要な機能分をダウンロードしておきましょうね。
ダウンロードし終わったら以下のフォルダに、そのモデルを格納します。
C:\(任意のフォルダ)\stable-diffusion-webui\extensions\sd-webui-controlnet\models
これでControlNetを使う準備が整いました。
ControlNetの使い方
では、実際に使っていくわけですが、まずはControlNetにおける機能について私の所見を交えて簡単に解説していきます。
〇 canny
割と万能な感じなので、お試しをするならまずはここからです。
〇 depth
奥行きのある立体的な絵を変える際に良さそうなものっぽいです。
〇 hed
詳細を保持するようで、色や極端ではない画風を変更するのに向いたものっぽいです。
〇 normal
被写体の形は変えず背景などを変えたい場合に使うものっぽい?
〇 Openpose
ポーズスケルトン(棒人間)を被写体から抽出しポーズを反映するためのものです。
これにより、構図を決定するのが飛躍的に楽になります。
〇 Scribbles
落書きレベルの線画をベースに描写をするもの。
〇 fake Scribbles
逆に写真などの被写体から簡単な線を抜き出すもの。
〇 segmentation
物体それぞれの占有率を特定してその場所に変更を加えるもの?
同じものと認識できる場所が広いほど精度が上がりやすいっぽい。
以上、簡単ではありますが、機能の説明でした。
では、実際に使っていきましょう。
txt2imgもしくはimg2imgタブの一番下の方に、以下のように折りたたまれてひっそりとControlNetがあります。
クリックして展開しましょう。
先ほどimg2imgで説明したのと同じような手順です。
① 元になる画像をドラッグアンドドロップなどで読み込ませます。
② Enableにチェックを入れます
③ PreprocessorとModelを選びます。
選ぶものは機能とモデルが一致する必要があります。
以下にCanyで使ってみた場合の例をご紹介します。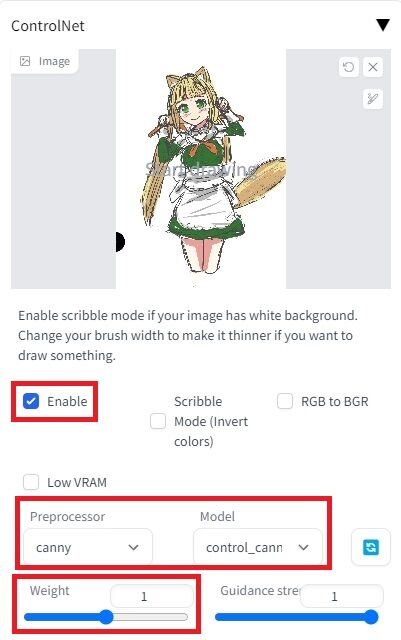
Weightは、元の絵にどれくらい近くするかを表しております。
下げれば下げるほど、元の絵から離れていきます。
個人的な感触では0.5ぐらいが分水嶺かなと感じましたので、そこを起点に調節していくのが良いと思います。
では、今回も田中さんの絵を拝借して、どんな感じになるか試していきます。
元の絵はこちら。リリーです。
誰よ? ってなる方も多いと思うのですが、私の作品の登場人物の一人ですね!
オリキャラなのと、私の脳内で完全に補完できるので、かなりやりやすかったです。
では、Cannyでこねくり回した結果がこちら。
いやぁ、良いですなぁ。元は京夜さんの絵からスタートしている彼女ですが、自分である程度再現できるってのが嬉しいです。
それも田中さんの可愛い絵があっての事なので、ありがとう!ありがとう!
と言う訳で、かなり服が変わってしまったりするものの、これはプロンプトの利かせ方や、元の絵の線によるものと思われます。
あと手がね、どうしてもAIちゃんはまだ苦手なので、ここは時間が解決してくれるでしょう。
モデルの方である程度こなれてくれば、手も綺麗になると思うので、今はこれで十分です。
特徴的なのは構図をちゃんと踏襲している点ですよね。
バランスとかを保ちつつ破綻しないようにうまく編集してくれるので、かなり優秀だと感じました。
また、もう一枚、こちらは花騎士のナンテンさんです。
元の絵はこちら。
彼女の色っぽさが田中さん風で面白い感じに出てるなぁと私は思うのですが、これをAIちゃんに任せるとこうなります。
うーむ、構図が完璧すぎる。
ある程度、空間をちゃんと把握して置き換えられているのが凄い。
対して田中さん風がちょっと薄れてしまうのが個人的に残念なところです。
私の今の技術力ではその辺りを上手く組み入れて編集するというのはちと難しいなぁと感じました。
勿論、画風に対して好みの問題もあると思うので、その辺りはご自分の好みのモデルと出力を探していくことになると思います。
と言う訳で、いかがだったでしょうか?
私は、かなり面白い道具になってきたなと言う感じがします。
特に絵師さんは本当に雑で良いのでラフや線画をささっと描ければ、ざっくりと完成まで持っていけると思うので、使いこなせば強い武器になると思います。
皆さんも是非、内に秘めた魂を爆発させる道具の一つとして、活用して見て下さい。
総評 そろそろ手を出せる範囲に入ってきた
前の記事でも書きましたが私は割と時間がある方なのと、試行錯誤は好きな研究者肌なので良いのですが、これを一般の、しかも初心者の皆様がやるのは、相変わらず大変であると思います。
一方で今回の記事に書いたような使い方をするだけであるなら、一時期と比べれば、かなり楽になってきたと感じます。
① 環境を用意するのが大変
こればっかりは、もう資金力との兼ね合いなので何ともです。
しかしながら、私のようにPC主体に活動されている方は、この機会にスペックアップも視野に検討する余地は出て来たなとは感じます。
特に、ただ絵を出力するだけであればVRAM8Gクラスのグラボで良いので(場合によっては6G)かなり敷居は下がると思いました。
ノートでも恐らくは、このレベルなら今の時点でなら描画は出来ます(トレーニングは無理)
ちなみにドスパラのノートはスペックの割に作りもよく、かなりコストパフォーマンスは高いと思うのですが……
欠点として、後負荷時での発熱が凄いので、ファンの音がヤバいってのがあります。
特にAI使用時はフル稼働するので、キーボードにすら熱が伝わって熱くて打てないレベルになることも。
これはドスパラに限らず全てのノートの宿命なので、持ち運ばない・場所があるならデスクトップをお勧めします。
② 仕組みや使い方を理解するのが大変
基本事項を理解するだけでもかなり大変な上に、最近の更新頻度がとんでもなく高いせいで、そのハードルが更に爆上がり状態です。
まぁ、数年もすればこの勢いも落ち着いてくるとは思うので、それまで待つというのも手ですが、その時には先に逝った人たちに追いつくのは厳しいと思います。
本当に技術の転換点であるので、もし興味のある方は今のうちにある程度触っておくほうが、良いとは思います。
③ 絵師さんや世間の感情が落ち着いていない
個人的には、感情的にAIを忌避するのは仕方ないにせよ、それでチャンスを逃した人もかなり多いんだろうなぁと言う印象です。
あくまで個人的な感想でしかないのですが、先日、クリップスタジオさんがAI機能の試験導入を見送ったことは割と致命的だよなーと感じております。
お安いお値段設定で割と重宝していたツールだったので、残念。
とは言え、これが今の絵師さんの総意という事でもあるので、私はしょうがないよね、と言う感想です。
逆にAIを積極的に取り入れたPhotoshopはこれから伸びていくかもしれませんね。
けど高いんですよね、アドビ(本音)
今回は試験的に、田中さんのご協力を経てこんな感じで記事をまとめてみました。
ご協力いただきました田中さんには、改めてお礼申し上げます。
そんな感じで、自分の絵を作り出してみたいなと思っている紳士淑女の皆様の力に少しでもなれたらなら幸いです。
けど、重ねて何度も申し上げますが、人の絵は勝手に使っちゃダメですからね?
今回の記事は以上になります。
お読みいただき、ありがとうございました。


コメント
おっすくれすさんだよ。
相変わらず更新のたびに進化が加速していくAI技術はほんとすごいね。
すごいんだけど、やっぱりなんだろうかな。今回は元の絵があるから余計にそうなんだろうけど、とりあえず綺麗にはできるけど、あくまで学習した範囲でそれらしくしてるだけって感じで、いやそれはそれで十分スゴイのだが。しかしなんじゃろね?エレクトーンに付いてる自動演奏みたいな話で、正確だけど表現力ゼロみたいなそな感じ。参考にはなるけどゴールにはならんみたいな。たぶん、今回元絵を提供してくれたお絵描きマン氏のゴールはまた別のところにあるんじゃねぇかな。と思う。知らんけどな。
というか、見るたびに要求スペック上がっててそこに一番驚いてる気がするな。
資金とか知識とか、導入ハードルが初期のパソコン通信みたいな絶壁感があって、まだまだ誰でも使える技術ってところには落ち着てこなさそうだなあ。
>>1
くれすさんへ
こんにちはー
コメントし辛いこちらに、いつもありがとうございます!
AIの技術の進歩は凄いんですよねぇ
私も着いていけてないのですが、一応、流れだけでも追えれば忘備録くらいにはなるかなぁと書いてます
あー、AIの絵が魅力的に映らない問題は凄く分かります
多分、今の段階では皆さんが驚くような凄い絵?画力?みたいなものを中心に描かれているんですよね
なのでAIっぽい絵が量産されているのが今の風潮と私は感じてます
ただ、ここからそれを使いこなして新たな画風にする人たちは出てくるんだと思います
今回の記事では、あくまで一例として今回は絵師さんの絵にご協力いただきましたが、私もくれすさんのおっしゃる通りで、出来上がった絵に関して言えば「その方の絵ではないな」と思ってます
というか、魅力を引き出せればよかったんですが、しょせん一介のオタクには無理でした
まぁ、私の手が少しでも入った時点でそれはそういうモノなんでしょうね
要求スペックは、描画だけなら最初からあまり変わってない感じでしょうか
ただご自分の絵を描かせたいならトレーニングは必須になるので、そこでそれなりのスペックが要求される感じになっちゃいますね
クラウドを使ってトレーニングする方法もあるので、知識さえあれば必ずしもPCスペックは必要ないんですが(それでも制約はある)、そもそも知識云々を得るのが大変でしょうし、結局、まだ多くの方にとって厳しいのが現状ですね
ぱ、パソコン通信はスペックもそうですが、そもそも回線料金が……
そう考えると良い世の中になったものですね
ではではー